python实现协同过滤推荐算法完整代码示例
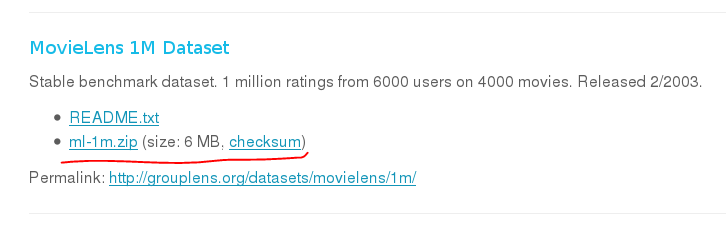
测试数据
http://grouplens.org/datasets/movielens/
协同过滤推荐算法主要分为:
1、基于用户。根据相邻用户,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表进行推荐
2、基于物品。如喜欢物品A的用户都喜欢物品C,那么可以知道物品A与物品C的相似度很高,而用户C喜欢物品A,那么可以推断出用户C也可能喜欢物品C。
不同的数据、不同的程序猿写出的协同过滤推荐算法不同,但其核心是一致的:
1、收集用户的偏好
1)不同行为分组
2)不同分组进行加权计算用户的总喜好
3)数据去噪和归一化
2、找到相似用户(基于用户)或者物品(基于物品)
3、计算相似度并进行排序。根据相似度为用户进行推荐
本次实例过程:
1、初始化数据
获取movies和ratings
转换成数据userDict表示某个用户的所有电影的评分集合,并对评分除以5进行归一化
转换成数据ItemUser表示某部电影参与评分的所有用户集合
2、计算所有用户与userId的相似度
找出所有观看电影与userId有交集的用户
对这些用户循环计算与userId的相似度
获取A用户与userId的并集。格式为:{'电影ID',[A用户的评分,userId的评分]},没有评分记为0
计算A用户与userId的余弦距离,越大越相似
3、根据相似度生成推荐电影列表
4、输出推荐列表和准确率
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from numpy import *
import time
from texttable import Texttable
class CF:
def __init__(self, movies, ratings, k=5, n=10):
self.movies = movies
self.ratings = ratings
# 邻居个数
self.k = k
# 推荐个数
self.n = n
# 用户对电影的评分
# 数据格式{'UserID:用户ID':[(MovieID:电影ID,Rating:用户对电影的评星)]}
self.userDict = {}
# 对某电影评分的用户
# 数据格式:{'MovieID:电影ID',[UserID:用户ID]}
# {'1',[1,2,3..],...}
self.ItemUser = {}
# 邻居的信息
self.neighbors = []
# 推荐列表
self.recommandList = []
self.cost = 0.0
# 基于用户的推荐
# 根据对电影的评分计算用户之间的相似度
def recommendByUser(self, userId):
self.formatRate()
# 推荐个数 等于 本身评分电影个数,用户计算准确率
self.n = len(self.userDict[userId])
self.getNearestNeighbor(userId)
self.getrecommandList(userId)
self.getPrecision(userId)
# 获取推荐列表
def getrecommandList(self, userId):
self.recommandList = []
# 建立推荐字典
recommandDict = {}
for neighbor in self.neighbors:
movies = self.userDict[neighbor[1]]
for movie in movies:
if(movie[0] in recommandDict):
recommandDict[movie[0]] += neighbor[0]
else:
recommandDict[movie[0]] = neighbor[0]
# 建立推荐列表
for key in recommandDict:
self.recommandList.append([recommandDict[key], key])
self.recommandList.sort(reverse=True)
self.recommandList = self.recommandList[:self.n]
# 将ratings转换为userDict和ItemUser
def formatRate(self):
self.userDict = {}
self.ItemUser = {}
for i in self.ratings:
# 评分最高为5 除以5 进行数据归一化
temp = (i[1], float(i[2]) / 5)
# 计算userDict {'1':[(1,5),(2,5)...],'2':[...]...}
if(i[0] in self.userDict):
self.userDict[i[0]].append(temp)
else:
self.userDict[i[0]] = [temp]
# 计算ItemUser {'1',[1,2,3..],...}
if(i[1] in self.ItemUser):
self.ItemUser[i[1]].append(i[0])
else:
self.ItemUser[i[1]] = [i[0]]
# 找到某用户的相邻用户
def getNearestNeighbor(self, userId):
neighbors = []
self.neighbors = []
# 获取userId评分的电影都有那些用户也评过分
for i in self.userDict[userId]:
for j in self.ItemUser[i[0]]:
if(j != userId and j not in neighbors):
neighbors.append(j)
# 计算这些用户与userId的相似度并排序
for i in neighbors:
dist = self.getCost(userId, i)
self.neighbors.append([dist, i])
# 排序默认是升序,reverse=True表示降序
self.neighbors.sort(reverse=True)
self.neighbors = self.neighbors[:self.k]
# 格式化userDict数据
def formatuserDict(self, userId, l):
user = {}
for i in self.userDict[userId]:
user[i[0]] = [i[1], 0]
for j in self.userDict[l]:
if(j[0] not in user):
user[j[0]] = [0, j[1]]
else:
user[j[0]][1] = j[1]
return user
# 计算余弦距离
def getCost(self, userId, l):
# 获取用户userId和l评分电影的并集
# {'电影ID':[userId的评分,l的评分]} 没有评分为0
user = self.formatuserDict(userId, l)
x = 0.0
y = 0.0
z = 0.0
for k, v in user.items():
x += float(v[0]) * float(v[0])
y += float(v[1]) * float(v[1])
z += float(v[0]) * float(v[1])
if(z == 0.0):
return 0
return z / sqrt(x * y)
# 推荐的准确率
def getPrecision(self, userId):
user = [i[0] for i in self.userDict[userId]]
recommand = [i[1] for i in self.recommandList]
count = 0.0
if(len(user) >= len(recommand)):
for i in recommand:
if(i in user):
count += 1.0
self.cost = count / len(recommand)
else:
for i in user:
if(i in recommand):
count += 1.0
self.cost = count / len(user)
# 显示推荐列表
def showTable(self):
neighbors_id = [i[1] for i in self.neighbors]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(["t", "t", "t", "t"])
table.set_cols_align(["l", "l", "l", "l"])
rows = []
rows.append([u"movie ID", u"Name", u"release", u"from userID"])
for item in self.recommandList:
fromID = []
for i in self.movies:
if i[0] == item[1]:
movie = i
break
for i in self.ItemUser[item[1]]:
if i in neighbors_id:
fromID.append(i)
movie.append(fromID)
rows.append(movie)
table.add_rows(rows)
print(table.draw())
# 获取数据
def readFile(filename):
files = open(filename, "r", encoding="utf-8")
# 如果读取不成功试一下
# files = open(filename, "r", encoding="iso-8859-15")
data = []
for line in files.readlines():
item = line.strip().split("::")
data.append(item)
return data
# -------------------------开始-------------------------------
start = time.clock()
movies = readFile("/home/hadoop/Python/CF/movies.dat")
ratings = readFile("/home/hadoop/Python/CF/ratings.dat")
demo = CF(movies, ratings, k=20)
demo.recommendByUser("100")
print("推荐列表为:")
demo.showTable()
print("处理的数据为%d条" % (len(demo.ratings)))
print("准确率: %.2f %%" % (demo.cost * 100))
end = time.clock()
print("耗费时间: %f s" % (end - start))
总结
以上就是本文关于python实现协同过滤推荐算法完整代码示例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!