python并发2之使用asyncio处理并发
asyncio
在Python 2的时代,高性能的网络编程主要是使用Twisted、Tornado和Gevent这三个库,但是它们的异步代码相互之间既不兼容也不能移植。如上一节说的,Gvanrossum希望在Python 3 实现一个原生的基于生成器的协程库,其中直接内置了对异步IO的支持,这就是asyncio,它在Python 3.4被引入到标准库。
asyncio 这个包使用事件循环驱动的协程实现并发。
asyncio 包在引入标准库之前代号 “Tulip”(郁金香),所以在网上搜索资料时,会经常看到这种花的名字。
什么是事件循环?
wiki 上说:事件循环是”一种等待程序分配事件或者消息的编程架构“。基本上来说事件循环就是:”当A发生时,执行B"。或者用最简单的例子来解释这一概念就是每个浏览器中都存在的JavaScript事件循环。当你点击了某个东西(“当A发生时”),这一点击动作会发送给JavaScript的事件循环,并检查是否存在注册过的onclick 回调来处理这一点击(执行B)。只要有注册过的回调函数就会伴随点击动作的细节信息被执行。事件循环被认为是一种虚幻是因为它不停的手机事件并通过循环来发如何应对这些事件。
对 Python 来说,用来提供事件循环的 asyncio 被加入标准库中。asyncio 重点解决网络服务中的问题,事件循环在这里将来自套接字(socket)的 I/O 已经准备好读和/或写作为“当A发生时”(通过selectors模块)。除了 GUI 和 I/O,事件循环也经常用于在别的线程或子进程中执行代码,并将事件循环作为调节机制(例如,合作式多任务)。如果你恰好理解 Python 的 GIL,事件循环对于需要释放 GIL 的地方很有用。
线程与协程
我们先看两断代码,分别用 threading 模块和asyncio 包实现的一段代码。
# sinner_thread.py
import threading
import itertools
import time
import sys
class Signal: # 这个类定义一个可变对象,用于从外部控制线程
go = True
def spin(msg, signal): # 这个函数会在单独的线程中运行,signal 参数是前边定义的Signal类的实例
write, flush = sys.stdout.write, sys.stdout.flush
for char in itertools.cycle('|/-\\'): # itertools.cycle 函数从指定的序列中反复不断地生成元素
status = char + ' ' + msg
write(status)
flush()
write('\x08' * len(status)) # 使用退格符把光标移回行首
time.sleep(.1) # 每 0.1 秒刷新一次
if not signal.go: # 如果 go属性不是 True,退出循环
break
write(' ' * len(status) + '\x08' * len(status)) # 使用空格清除状态消息,把光标移回开头
def slow_function(): # 模拟耗时操作
# 假装等待I/O一段时间
time.sleep(3) # 调用sleep 会阻塞主线程,这么做事为了释放GIL,创建从属线程
return 42
def supervisor(): # 这个函数设置从属线程,显示线程对象,运行耗时计算,最后杀死进程
signal = Signal()
spinner = threading.Thread(target=spin,
args=('thinking!', signal))
print('spinner object:', spinner) # 显示线程对象 输出 spinner object: <Thread(Thread-1, initial)>
spinner.start() # 启动从属进程
result = slow_function() # 运行slow_function 行数,阻塞主线程。同时丛书线程以动画形式旋转指针
signal.go = False
spinner.join() # 等待spinner 线程结束
return result
def main():
result = supervisor()
print('Answer', result)
if __name__ == '__main__':
main()
执行一下,结果大致是这个样子:
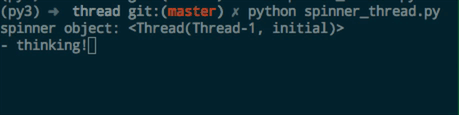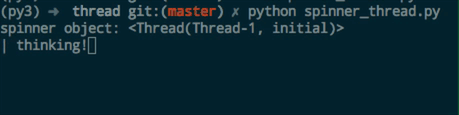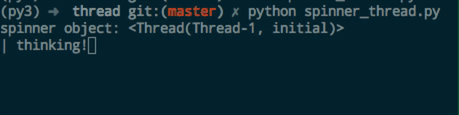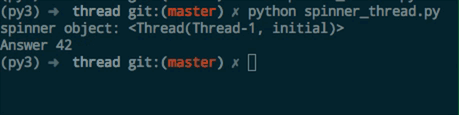
这是一个动图,“thinking" 前的 线是会动的(为了录屏,我把sleep 的时间调大了)
python 并没有提供终止线程的API,所以若想关闭线程,必须给线程发送消息。这里我们使用signal.go 属性:在主线程中把它设置为False后,spinner 线程会接收到,然后退出
现在我们再看下使用 asyncio 包的版本:
# spinner_asyncio.py
# 通过协程以动画的形式显示文本式旋转指针
import asyncio
import itertools
import sys
@asyncio.coroutine # 打算交给asyncio 处理的协程要使用 @asyncio.coroutine 装饰
def spin(msg):
write, flush = sys.stdout.write, sys.stdout.flush
for char in itertools.cycle('|/-\\'): # itertools.cycle 函数从指定的序列中反复不断地生成元素
status = char + ' ' + msg
write(status)
flush()
write('\x08' * len(status)) # 使用退格符把光标移回行首
try:
yield from asyncio.sleep(0.1) # 使用 yield from asyncio.sleep(0.1) 代替 time.sleep(.1), 这样的休眠不会阻塞事件循环
except asyncio.CancelledError: # 如果 spin 函数苏醒后抛出 asyncio.CancelledError 异常,其原因是发出了取消请求
break
write(' ' * len(status) + '\x08' * len(status)) # 使用空格清除状态消息,把光标移回开头
@asyncio.coroutine
def slow_function(): # 5 现在此函数是协程,使用休眠假装进行I/O 操作时,使用 yield from 继续执行事件循环
# 假装等待I/O一段时间
yield from asyncio.sleep(3) # 此表达式把控制权交给主循环,在休眠结束后回复这个协程
return 42
@asyncio.coroutine
def supervisor(): #这个函数也是协程,因此可以使用 yield from 驱动 slow_function
spinner = asyncio.async(spin('thinking!')) # asyncio.async() 函数排定协程的运行时间,使用一个 Task 对象包装spin 协程,并立即返回
print('spinner object:', spinner) # Task 对象,输出类似 spinner object: <Task pending coro=<spin() running at spinner_asyncio.py:6>>
# 驱动slow_function() 函数,结束后,获取返回值。同事事件循环继续运行,
# 因为slow_function 函数最后使用yield from asyncio.sleep(3) 表达式把控制权交给主循环
result = yield from slow_function()
# Task 对象可以取消;取消后会在协程当前暂停的yield处抛出 asyncio.CancelledError 异常
# 协程可以捕获这个异常,也可以延迟取消,甚至拒绝取消
spinner.cancel()
return result
def main():
loop = asyncio.get_event_loop() # 获取事件循环引用
# 驱动supervisor 协程,让它运行完毕;这个协程的返回值是这次调用的返回值
result = loop.run_until_complete(supervisor())
loop.close()
print('Answer', result)
if __name__ == '__main__':
main()
除非想阻塞主线程,从而冻结事件循环或整个应用,否则不要再 asyncio 协程中使用 time.sleep().
如果协程需要在一段时间内什么都不做,应该使用 yield from asyncio.sleep(DELAY)
使用 @asyncio.coroutine 装饰器不是强制要求,但建议这么做因为这样能在代码中突显协程,如果还没从中产出值,协程就把垃圾回收了(意味着操作未完成,可能有缺陷),可以发出警告。这个装饰器不会预激协程。
这两段代码的执行结果基本相同,现在我们看一下两段代码的核心代码 supervisor 主要区别:
- asyncio.Task 对象差不多与 threading.Thread 对象等效(Task 对象像是实现写作时多任务的库中的绿色线程
- Task 对象用于驱动协程,Thread 对象用于调用可调用的对象
- Task 对象不由自己动手实例化,而是通过把协程传给 asyncio.async(...) 函数或 loop.create_task(...) 方法获取
- 获取的Task 对象已经排定了运行时间;Thread 实例必须调用start方法,明确告知它运行
- 在线程版supervisor函数中,slow_function 是普通的函数,由线程直接调用,而异步版的slow_function 函数是协程,由yield from 驱动。
- 没有API能从外部终止线程,因为线程随时可能被中断。而如果想终止任务,可以使用Task.cancel() 实例方法,在协程内部抛出CancelledError 异常。协程可以在暂停的yield 处捕获这个异常,处理终止请求
- supervisor 协程必须在main 函数中由loop.run_until_complete 方法执行。
协程和线程相比关键的一个优点是,线程必须记住保留锁,去保护程序中的重要部分,防止多步操作再执行的过程中中断,防止山水处于于晓状态协程默认会做好保护,我们必须显式产出(使用yield 或 yield from 交出控制权)才能让程序的余下部分运行。
asyncio.Future:故意不阻塞
asynci.Future 类与 concurrent.futures.Future 类的接口基本一致,不过实现方式不同,不可互换。
上一篇[python并发 1:使用 futures 处理并发]()我们介绍过 concurrent.futures.Future 的 future,在 concurrent.futures.Future 中,future只是调度执行某物的结果。在 asyncio 包中,BaseEventLoop.create_task(...) 方法接收一个协程,排定它的运行时间,然后返回一个asyncio.Task 实例(也是asyncio.Future 类的实例,因为 Task 是 Future 的子类,用于包装协程。(在 concurrent.futures.Future 中,类似的操作是Executor.submit(...))。
与concurrent.futures.Future 类似,asyncio.Future 类也提供了
- .done() 返回布尔值,表示Future 是否已经执行
- .add_done_callback() 这个方法只有一个参数,类型是可调用对象,Future运行结束后会回调这个对象。
- .result() 这个方法没有参数,因此不能指定超时时间。 如果调用 .result() 方法时期还没有运行完毕,会抛出asyncio.InvalidStateError 异常。
对应的 concurrent.futures.Future 类中的 Future 运行结束后调用result(), 会返回可调用对象的结果或者抛出执行可调用对象时抛出的异常,如果是 Future 没有运行结束时调用 f.result()方法,这时会阻塞调用方所在的线程,直到有结果返回。此时result 方法还可以接收 timeout 参数,如果在指定的时间内 Future 没有运行完毕,会抛出 TimeoutError 异常。
我们使用asyncio.Future 时, 通常使用yield from,从中获取结果,而不是使用 result()方法 yield from 表达式在暂停的协程中生成返回值,回复执行过程。
asyncio.Future 类的目的是与 yield from 一起使用,所以通常不需要使用以下方法:
- 不需调用 my_future.add_down_callback(...), 因为可以直接把想在 future 运行结束后的操作放在协程中 yield from my_future 表达式的后边。(因为协程可以暂停和恢复函数)
- 无需调用 my_future.result(), 因为 yield from 产生的结果就是(result = yield from my_future)
在 asyncio 包中,可以使用yield from 从asyncio.Future 对象中产出结果。这也就意味着我们可以这么写:
res = yield from foo() # foo 可以是协程函数,也可以是返回 Future 或 task 实例的普通函数
asyncio.async(...)* 函数
asyncio.async(coro_or_future, *, loop=None)
这个函数统一了协程和Future: 第一个参数可以是二者中的任意一个。如果是Future 或者 Task 对象,就直接返回,如果是协程,那么async 函数会自动调用 loop.create_task(...) 方法创建 Task 对象。 loop 参数是可选的,用于传入事件循环; 如果没有传入,那么async函数会通过调用asyncio.get_event_loop() 函数获取循环对象。
BaseEventLoop.create_task(coro)
这个方法排定协程的执行时间,返回一个 asyncio.Task 对象。如果在自定义的BaseEventLoop 子类上调用,返回的对象可能是外部库中与Task类兼容的某个类的实例。
BaseEventLoop.create_task() 方法只在Python3.4.2 及以上版本可用。 Python3.3 只能使用 asyncio.async(...)函数。
如果想在Python控制台或者小型测试脚本中实验future和协程,可以使用下面的片段:
import asyncio def run_sync(coro_or_future): loop = asyncio.get_event_loop() return loop.run_until_complete(coro_or_future) a = run_sync(some_coroutine())
使用asyncio 和 aiohttp 包下载
现在,我们了解了asyncio 的基础知识,是时候使用asyncio 来重写我们 上一篇 [python并发 1:使用 futures 处理并发]() 下载国旗的脚本了。
先看一下代码:
import asyncio
import aiohttp # 需要pip install aiohttp
from flags import save_flag, show, main, BASE_URL
@asyncio.coroutine # 我们知道,协程应该使用 asyncio.coroutine 装饰
def get_flag(cc):
url = "{}/{cc}/{cc}.gif".format(BASE_URL, cc=cc.lower())
# 阻塞的操作通过协程实现,客户代码通过yield from 把指责委托给协程,以便异步操作
resp = yield from aiohttp.request('GET', url)
# 读取也是异步操作
image = yield from resp.read()
return image
@asyncio.coroutine
def download_one(cc): # 这个函数也必须是协程,因为用到了yield from
image = yield from get_flag(cc)
show(cc)
save_flag(image, cc.lower() + '.gif')
return cc
def download_many(cc_list):
loop = asyncio.get_event_loop() # 获取事件序号底层实现的引用
to_do = [download_one(cc) for cc in sorted(cc_list)] # 调用download_one 获取各个国旗,构建一个生成器对象列表
# 虽然函数名称是wait 但它不是阻塞型函数,wait 是一个协程,等传给他的所有协程运行完毕后结束
wait_coro = asyncio.wait(to_do)
res, _ = loop.run_until_complete(wait_coro) # 执行事件循环,知道wait_coro 运行结束;事件循环运行的过程中,这个脚本会在这里阻塞。
loop.close() # 关闭事件循环
return len(res)
if __name__ == '__main__':
main(download_many)
这段代码的运行简述如下:
- 在download_many 函数获取一个事件循环,处理调用download_one 函数生成的几个协程对象
- asyncio 事件循环一次激活各个协程
- 客户代码中的协程(get_flag)使用 yield from 把指责委托给库里的协程(aiohttp.request)时,控制权交还给事件循环,执行之前排定的协程
- 事件循环通过基于回调的底层API,在阻塞的操作执行完毕后获得通知。
- 获得通知后,主循环把结果发给暂停的协程
- 协程向前执行到下一个yield from 表达式,例如 get_flag 函数的yield from resp.read()。事件循环再次得到控制权,重复第4~6步,直到循环终止。
download_many 函数中,我们使用了 asyncio.wait(...) 函数,这个函数是一个协程,协程的参数是一个由future或者协程构成的可迭代对象;wait 会分别把各个协程包装进一个Task对象。最终的结果是,wait 处理的所有对象都通过某种方式变成Future 类的实例。
wait 是协程函数,因此,返回的是一个协程或者生成器对象;waite_coro 变量中存储的就是这种对象
loop.run_until_complete 方法的参数是一个future 或协程。如果是协程,run_until_complete 方法与 wait 函数一样,把协程包装进一个Task 对象中。这里 run_until_complete 方法把 wait_coro 包装进一个Task 对象中,由yield from 驱动。wait_coro 运行结束后返回两个参数,第一个参数是结束的future 第二个参数是未结束的future。
<section class="caption">wait</section>有两个命名参数,timeout 和 return_when 如果设置了可能会返回未结束的future。
有一点你可能也注意到了,我们重写了get_flags 函数,是因为之前用到的 requests 库执行的是阻塞型I/O操作。为了使用 asyncio 包,我们必须把函数改成异步版。
小技巧
如果你觉得 使用了协程后代码难以理解,可以采用 Python之父(Guido van Rossum)的建议,假装没有yield from。
已上边这段代码为例:
@asyncio.coroutine
def get_flag(cc):
url = "{}/{cc}/{cc}.gif".format(BASE_URL, cc=cc.lower())
resp = yield from aiohttp.request('GET', url)
image = yield from resp.read()
return image
# 把yield form 去掉
def get_flag(cc):
url = "{}/{cc}/{cc}.gif".format(BASE_URL, cc=cc.lower())
resp = aiohttp.request('GET', url)
image = resp.read()
return image
# 现在是不是清晰多了
知识点
在asyncio 包的API中使用 yield from 时,有个细节要注意:
使用asyncio包时,我们编写的异步代码中包含由asyncio本身驱动的协程(委派生成器),而生成器最终把指责委托给asyncio包或者第三方库中的协程。这种处理方式相当于架起了管道,让asyncio事件循环驱动执行底层异步I/O的库函数。
避免阻塞型调用
我们先看一个图,这个图显示了电脑从不同存储介质中读取数据的延迟情况:
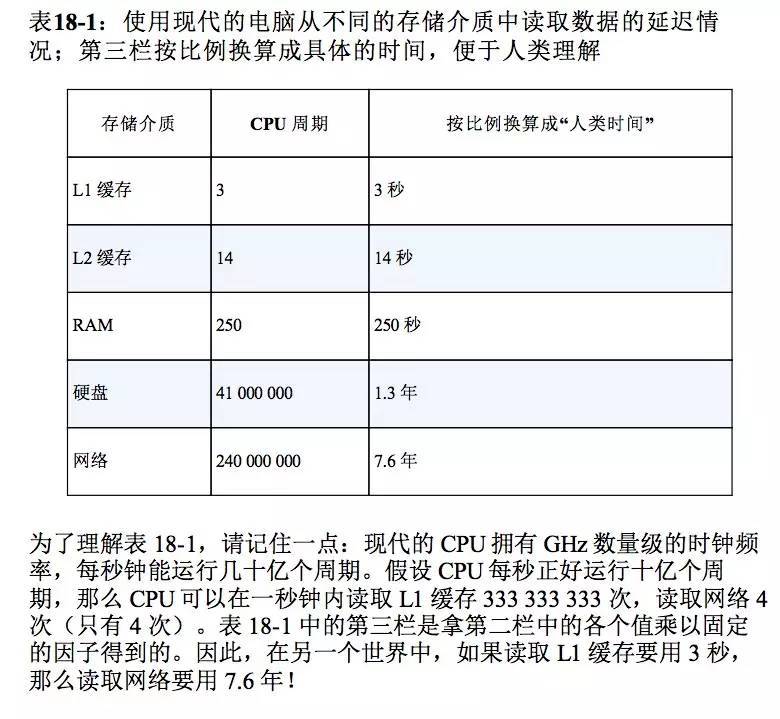
通过这个图,我们可以看到,阻塞型调用对于CPU来说是巨大的浪费。有什么办法可以避免阻塞型调用中止整个应用程序么?
有两种方法:
- 在单独的线程中运行各个阻塞型操作
- 把每个阻塞型操作转化成非阻塞的异步调用使用
当然我们推荐第二种方案,因为第一种方案中如果每个连接都使用一个线程,成本太高。
第二种我们可以使用把生成器当做协程使用的方式实现异步编程。对事件循环来说,调用回调与在暂停的协程上调用 .send() 方法效果差不多。各个暂停的协程消耗的内存比线程小的多。
现在,你应该能理解为什么 flags_asyncio.py 脚本比 flags.py 快的多了吧。
因为flags.py 是依次同步下载,每次下载都要用几十亿个CPU周期等待结果。而在flags_asyncio.py中,在download_many 函数中调用loop.run_until_complete 方法时,事件循环驱动各个download_one 协程,运行到yield from 表达式出,那个表达式又驱动各个 get_flag 协程,运行到第一个yield from 表达式处,调用 aiohttp.request()函数。这些调用不会阻塞,因此在零点几秒内所有请求都可以全部开始。
改进 asyncio 下载脚本
现在我们改进一下上边的 flags_asyncio.py,在其中添加上异常处理,计数器
import asyncio
import collections
from collections import namedtuple
from enum import Enum
import aiohttp
from aiohttp import web
from flags import save_flag, show, main, BASE_URL
DEFAULT_CONCUR_REQ = 5
MAX_CONCUR_REQ = 1000
Result = namedtuple('Result', 'status data')
HTTPStatus = Enum('Status', 'ok not_found error')
# 自定义异常用于包装其他HTTP货网络异常,并获取country_code,以便报告错误
class FetchError(Exception):
def __init__(self, country_code):
self.country_code = country_code
@asyncio.coroutine
def get_flag(cc):
# 此协程有三种返回结果:
# 1. 返回下载到的图片
# 2. HTTP 响应为404 时,抛出web.HTTPNotFound 异常
# 3. 返回其他HTTP状态码时, 抛出aiohttp.HttpProcessingError
url = "{}/{cc}/{cc}.gif".format(BASE_URL, cc=cc.lower())
resp = yield from aiohttp.request('GET', url)
if resp.status == 200:
image = yield from resp.read()
return image
elif resp.status == 404:
raise web.HttpNotFound()
else:
raise aiohttp.HttpProcessionError(
code=resp.status, message=resp.reason,
headers=resp.headers
)
@asyncio.coroutine
def download_one(cc, semaphore):
# semaphore 参数是 asyncio.Semaphore 类的实例
# Semaphore 类是同步装置,用于限制并发请求
try:
with (yield from semaphore):
# 在yield from 表达式中把semaphore 当成上下文管理器使用,防止阻塞整个系统
# 如果semaphore 计数器的值是所允许的最大值,只有这个协程会阻塞
image = yield from get_flag(cc)
# 退出with语句后 semaphore 计数器的值会递减,
# 解除阻塞可能在等待同一个semaphore对象的其他协程实例
except web.HTTPNotFound:
status = HTTPStatus.not_found
msg = 'not found'
except Exception as exc:
raise FetchError(cc) from exc
else:
save_flag(image, cc.lower() + '.gif')
status = HTTPStatus.ok
msg = 'ok'
return Result(status, cc)
@asyncio.coroutine
def downloader_coro(cc_list):
counter = collections.Counter()
# 创建一个 asyncio.Semaphore 实例,最多允许激活MAX_CONCUR_REQ个使用这个计数器的协程
semaphore = asyncio.Semaphore(MAX_CONCUR_REQ)
# 多次调用 download_one 协程,创建一个协程对象列表
to_do = [download_one(cc, semaphore) for cc in sorted(cc_list)]
# 获取一个迭代器,这个迭代器会在future运行结束后返回future
to_do_iter = asyncio.as_completed(to_do)
for future in to_do_iter:
# 迭代允许结束的 future
try:
res = yield from future # 获取asyncio.Future 对象的结果(也可以调用future.result)
except FetchError as exc:
# 抛出的异常都包装在FetchError 对象里
country_code = exc.country_code
try:
# 尝试从原来的异常 (__cause__)中获取错误消息
error_msg = exc.__cause__.args[0]
except IndexError:
# 如果在原来的异常中找不到错误消息,使用所连接异常的类名作为错误消息
error_msg = exc.__cause__.__class__.__name__
if error_msg:
msg = '*** Error for {}: {}'
print(msg.format(country_code, error_msg))
status = HTTPStatus.error
else:
status = res.status
counter[status] += 1
return counter
def download_many(cc_list):
loop = asyncio.get_event_loop()
coro = downloader_coro(cc_list)
counts = loop.run_until_complete(coro)
loop.close()
return counts
if __name__ == '__main__':
main(download_many)
由于协程发起的请求速度较快,为了防止向服务器发起太多的并发请求,使服务器过载,我们在download_coro 函数中创建一个asyncio.Semaphore 实例,然后把它传给download_one 函数。
<secion class="caption">Semaphore</section> 对象维护着一个内部计数器,若在对象上调用 .acquire() 协程方法,计数器则递减;若在对象上调用 .release() 协程方法,计数器则递增。计数器的值是在初始化的时候设定。
如果计数器大于0,那么调用 .acquire() 方法不会阻塞,如果计数器为0, .acquire() 方法会阻塞调用这个方法的协程,直到其他协程在同一个 Semaphore 对象上调用 .release() 方法,让计数器递增。
在上边的代码中,我们并没有手动调用 .acquire() 或 .release() 方法,而是在 download_one 函数中 把 semaphore 当做上下文管理器使用:
with (yield from semaphore): image = yield from get_flag(cc)
这段代码保证,任何时候都不会有超过 MAX_CONCUR_REQ 个 get_flag 协程启动。
使用 asyncio.as_completed 函数
因为要使用 yield from 获取 asyncio.as_completed 函数产出的future的结果,所以 as_completed 函数秩序在协程中调用。由于 download_many 要作为参数传给非协程的main 函数,我已我们添加了一个新的 downloader_coro 协程,让download_many 函数只用于设置事件循环。
使用Executor 对象,防止阻塞事件循环
现在我们回去看下上边关于电脑从不同存储介质读取数据的延迟情况图,有一个实时需要注意,那就是访问本地文件系统也会阻塞。
上边的代码中,save_flag 函数阻塞了客户代码与 asyncio 事件循环公用的唯一线程,因此保存文件时,整个应用程序都会暂停。为了避免这个问题,可以使用事件循环对象的 run_in_executor 方法。
asyncio 的事件循环在后台维护着一个ThreadPoolExecutor 对象,我们可以调用 run_in_executor 方法,把可调用的对象发给它执行。
下边是我们改动后的代码:
@asyncio.coroutine def download_one(cc, semaphore): try: with (yield from semaphore): image = yield from get_flag(cc) except web.HTTPNotFound: status = HTTPStatus.not_found msg = 'not found' except Exception as exc: raise FetchError(cc) from exc else: # 这里是改动部分 loop = asyncio.get_event_loop() # 获取事件循环的引用 loop.run_in_executor(None, save_flag, image, cc.lower() + '.gif') status = HTTPStatus.ok msg = 'ok' return Result(status, cc)
run_in_executor 方法的第一个参数是Executor 实例;如果设为None,使用事件循环的默认 ThreadPoolExecutor 实例。
从回调到future到协程
在接触协程之前,我们可能对回调有一定的认识,那么和回调相比,协程有什么改进呢?
python中的回调代码样式:
def stage1(response1): request2 = step1(response1) api_call2(request2, stage2) def stage2(response2): request3 = step3(response3) api_call3(request3, stage3) def stage3(response3): step3(response3) api_call1(request1, stage1)
上边的代码的缺陷:
- 容易出现回调地狱
- 代码难以阅读
在这个问题上,协程能发挥很大的作用。如果换成协程和yield from 结果做的异步代码,代码示例如下:
@asyncio.coroutine def three_stages(request1): response1 = yield from api_call1(request1) request2 = step1(response1) response2 = yield from api_call2(requests) request3 = step2(response2) response3 = yield from api_call3(requests) step3(response3) loop.create_task(three_stages(request1)
和之前的代码相比,这个代码就容易理解多了。如果异步调用 api_call1,api_call2,api_call3 会抛出异常,那么可以把相应的 yield from 表达式放在 try/except 块中处理异常。
使用协程必须习惯 yield from 表达式,并且协程不能直接调用,必须显式的排定协程的执行时间,或在其他排定了执行时间的协程中使用yield from 表达式吧它激活。如果不使用 loop.create_task(three_stages(request1)),那么什么都不会发生。
下面我们用一个实际的例子来演示一下:
每次下载发起多次请求
我们修改一下上边下载国旗的代码,使在下载国旗的同时还可以获取国家名称在保存图片的时候使用。
我们使用协程和yield from 解决这个问题:
@asyncio.coroutine
def http_get(url):
resp = yield from aiohttp.request('GET', url)
if resp.status == 200:
ctype = resp.headers.get('Content-type', '').lower()
if 'json' in ctype or url.endswith('json'):
data = yield from resp.json()
else:
data = yield from resp.read()
return data
elif resp.status == 404:
raise web.HttpNotFound()
else:
raise aiohttp.HttpProcessionError(
code=resp.status, message=resp.reason,
headers=resp.headers)
@asyncio.coroutine
def get_country(cc):
url = "{}/{cc}/metadata.json".format(BASE_URL, cc=cc.lower())
metadata = yield from http_get(url)
return metadata['country']
@asyncio.coroutine
def get_flag(cc):
url = "{}/{cc}/{cc}.gif".format(BASE_URL, cc=cc.lower())
return (yield from http_get(url))
@asyncio.coroutine
def download_one(cc, semaphore):
try:
with (yield from semaphore):
image = yield from get_flag(cc)
with (yield from semaphore):
country = yield from get_country(cc)
except web.HTTPNotFound:
status = HTTPStatus.not_found
msg = 'not found'
except Exception as exc:
raise FetchError(cc) from exc
else:
country = country.replace(' ', '_')
filename = '{}--{}.gif'.format(country, cc)
print(filename)
loop = asyncio.get_event_loop()
loop.run_in_executor(None, save_flag, image, filename)
status = HTTPStatus.ok
msg = 'ok'
return Result(status, cc)
在这段代码中,我们在download_one 函数中分别在 semaphore 控制的两个with 块中调用get_flag 和 get_country,是为了节约时间。
get_flag 的return 语句在外层加上括号,是因为() 的运算符优先级高,会先执行括号内的yield from 语句 返回的结果。如果不加 会报句法错误
加() ,相当于
image = yield from http_get(url) return image
如果不加(),那么程序会在 yield from 处中断,交出控制权,这时使用return 会报句法错误。
总结
这一篇我们讨论了:
- 对比了一个多线程程序和asyncio版,说明了多线程和异步任务之间的关系
- 比较了 asyncio.Future 类 和 concurrent.futures.Future 类的区别
- 如何使用异步编程管理网络应用中的高并发
- 在异步编程中,与回调相比,协程显著提升性能的方式
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。