Python数据拟合与广义线性回归算法学习
机器学习中的预测问题通常分为2类:回归与分类。
简单的说回归就是预测数值,而分类是给数据打上标签归类。
本文讲述如何用Python进行基本的数据拟合,以及如何对拟合结果的误差进行分析。
本例中使用一个2次函数加上随机的扰动来生成500个点,然后尝试用1、2、100次方的多项式对该数据进行拟合。
拟合的目的是使得根据训练数据能够拟合出一个多项式函数,这个函数能够很好的拟合现有数据,并且能对未知的数据进行预测。
代码如下:
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
from scipy.stats import norm
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
''''' 数据生成 '''
x = np.arange(0, 1, 0.002)
y = norm.rvs(0, size=500, scale=0.1)
y = y + x**2
''''' 均方误差根 '''
def rmse(y_test, y):
return sp.sqrt(sp.mean((y_test - y) ** 2))
''''' 与均值相比的优秀程度,介于[0~1]。0表示不如均值。1表示完美预测.这个版本的实现是参考scikit-learn官网文档 '''
def R2(y_test, y_true):
return 1 - ((y_test - y_true)**2).sum() / ((y_true - y_true.mean())**2).sum()
''''' 这是Conway&White《机器学习使用案例解析》里的版本 '''
def R22(y_test, y_true):
y_mean = np.array(y_true)
y_mean[:] = y_mean.mean()
return 1 - rmse(y_test, y_true) / rmse(y_mean, y_true)
plt.scatter(x, y, s=5)
degree = [1,2,100]
y_test = []
y_test = np.array(y_test)
for d in degree:
clf = Pipeline([('poly', PolynomialFeatures(degree=d)),
('linear', LinearRegression(fit_intercept=False))])
clf.fit(x[:, np.newaxis], y)
y_test = clf.predict(x[:, np.newaxis])
print(clf.named_steps['linear'].coef_)
print('rmse=%.2f, R2=%.2f, R22=%.2f, clf.score=%.2f' %
(rmse(y_test, y),
R2(y_test, y),
R22(y_test, y),
clf.score(x[:, np.newaxis], y)))
plt.plot(x, y_test, linewidth=2)
plt.grid()
plt.legend(['1','2','100'], loc='upper left')
plt.show()
该程序运行的显示结果如下:
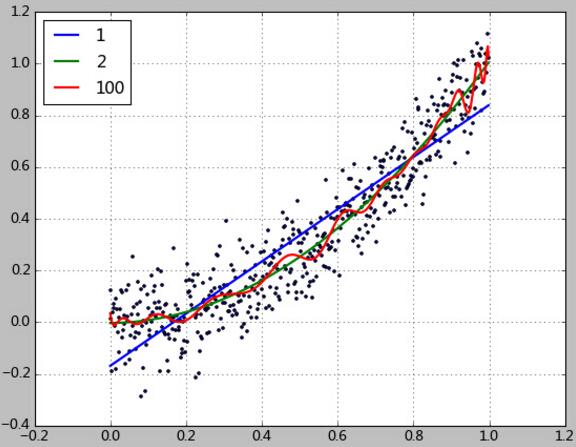
[-0.16140183 0.99268453]
rmse=0.13, R2=0.82, R22=0.58, clf.score=0.82
[ 0.00934527 -0.03591245 1.03065829]
rmse=0.11, R2=0.88, R22=0.66, clf.score=0.88
[ 6.07130354e-02 -1.02247150e+00 6.66972089e+01 -1.85696012e+04
......
-9.43408707e+12 -9.78954604e+12 -9.99872105e+12 -1.00742526e+13
-1.00303296e+13 -9.88198843e+12 -9.64452002e+12 -9.33298267e+12
-1.00580760e+12]
rmse=0.10, R2=0.89, R22=0.67, clf.score=0.89
显示出的coef_就是多项式参数。如1次拟合的结果为
y = 0.99268453x -0.16140183
这里我们要注意这几点:
1、误差分析。
做回归分析,常用的误差主要有均方误差根(RMSE)和R-平方(R2)。
RMSE是预测值与真实值的误差平方根的均值。这种度量方法很流行(Netflix机器学习比赛的评价方法),是一种定量的权衡方法。
R2方法是将预测值跟只使用均值的情况下相比,看能好多少。其区间通常在(0,1)之间。0表示还不如什么都不预测,直接取均值的情况,而1表示所有预测跟真实结果完美匹配的情况。
R2的计算方法,不同的文献稍微有不同。如本文中函数R2是依据scikit-learn官网文档实现的,跟clf.score函数结果一致。
而R22函数的实现来自Conway的著作《机器学习使用案例解析》,不同在于他用的是2个RMSE的比值来计算R2。
我们看到多项式次数为1的时候,虽然拟合的不太好,R2也能达到0.82。2次多项式提高到了0.88。而次数提高到100次,R2也只提高到了0.89。
2、过拟合。
使用100次方多项式做拟合,效果确实是高了一些,然而该模型的据测能力却极其差劲。
而且注意看多项式系数,出现了大量的大数值,甚至达到10的12次方。
这里我们修改代码,将500个样本中的最后2个从训练集中移除。然而在测试中却仍然测试所有500个样本。
clf.fit(x[:498, np.newaxis], y[:498])
这样修改后的多项式拟合结果如下:
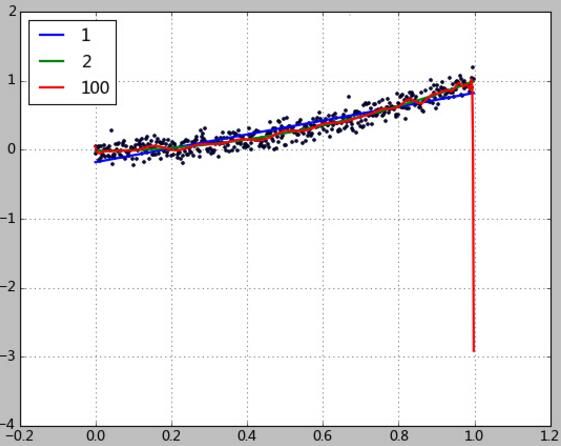
[-0.17933531 1.0052037 ]
rmse=0.12, R2=0.85, R22=0.61, clf.score=0.85
[-0.01631935 0.01922011 0.99193521]
rmse=0.10, R2=0.90, R22=0.69, clf.score=0.90
...
rmse=0.21, R2=0.57, R22=0.34, clf.score=0.57
仅仅只是缺少了最后2个训练样本,红线(100次方多项式拟合结果)的预测发生了剧烈的偏差,R2也急剧下降到0.57。
而反观1,2次多项式的拟合结果,R2反而略微上升了。
这说明高次多项式过度拟合了训练数据,包括其中大量的噪音,导致其完全丧失了对数据趋势的预测能力。前面也看到,100次多项式拟合出的系数数值无比巨大。人们自然想到通过在拟合过程中限制这些系数数值的大小来避免生成这种畸形的拟合函数。
其基本原理是将拟合多项式的所有系数绝对值之和(L1正则化)或者平方和(L2正则化)加入到惩罚模型中,并指定一个惩罚力度因子w,来避免产生这种畸形系数。
这样的思想应用在了岭(Ridge)回归(使用L2正则化)、Lasso法(使用L1正则化)、弹性网(Elastic net,使用L1+L2正则化)等方法中,都能有效避免过拟合。更多原理可以参考相关资料。
下面以岭回归为例看看100次多项式的拟合是否有效。将代码修改如下:
clf = Pipeline([('poly', PolynomialFeatures(degree=d)),
('linear', linear_model.Ridge ())])
clf.fit(x[:400, np.newaxis], y[:400])
结果如下:
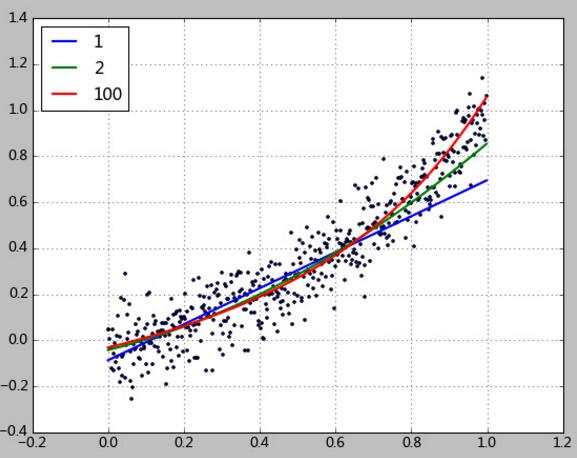
[ 0. 0.75873781]
rmse=0.15, R2=0.78, R22=0.53, clf.score=0.78
[ 0. 0.35936882 0.52392172]
rmse=0.11, R2=0.87, R22=0.64, clf.score=0.87
[ 0.00000000e+00 2.63903249e-01 3.14973328e-01 2.43389461e-01
1.67075328e-01 1.10674280e-01 7.30672237e-02 4.88605804e-02
......
3.70018540e-11 2.93631291e-11 2.32992690e-11 1.84860002e-11
1.46657377e-11]
rmse=0.10, R2=0.90, R22=0.68, clf.score=0.90
可以看到,100次多项式的系数参数变得很小。大部分都接近于0.
另外值得注意的是,使用岭回归之类的惩罚模型后,1次和2次多项式回归的R2值可能会稍微低于基本线性回归。
然而这样的模型,即使使用100次多项式,在训练400个样本,预测500个样本的情况下不仅有更小的R2误差,而且还具备优秀的预测能力。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。