python队列通信:rabbitMQ的使用(实例讲解)
(一)、前言
为什么引入消息队列?
1.程序解耦
2.提升性能
3.降低多业务逻辑复杂度
(二)、python操作rabbit mq
rabbitmq配置安装基本使用参见上节文章,不再复述。
若想使用python操作rabbitmq,需安装pika模块,直接pip安装:
pip install pika
1.最简单的rabbitmq producer端与consumer端对话:
producer:
#Author :ywq
import pika
auth=pika.PlainCredentials('ywq','qwe') #save auth indo
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth)) #connect to rabbit
channel = connection.channel() #create channel
channel.queue_declare(queue='hello') #declare queue
#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!') #the body is the msg content
print(" [x] Sent 'Hello World!'")
connection.close()
consumer:
#Author :ywq
import pika
auth=pika.PlainCredentials('ywq','qwe') #auth info
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth)) #connect to rabbit
channel = connection.channel() #create channel
channel.queue_declare(queue='hello') #decalre queue
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
消息传递消费过程中,可以在rabbit web管理页面实时查看队列消息信息。
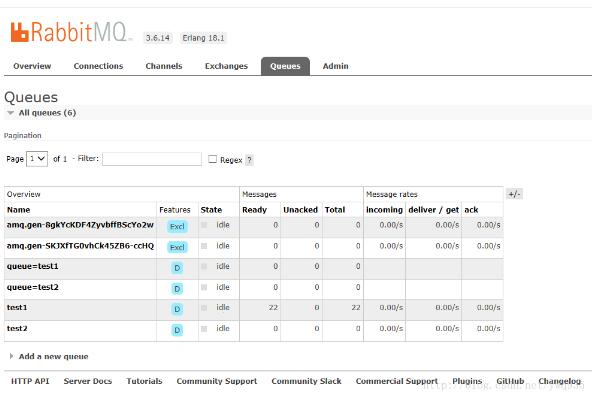
2.持久化的消息队列,避免宕机等意外情况造成消息队列丢失。
consumer端无需改变,在producer端代码内加上两个属性,分别使消息持久化、队列持久化,只选其一还是会出现消息丢失,必须同时开启:
delivery_mode=2 #make msg persisdent durable=True
属性插入位置见如下代码(producer端):
#Author :ywq
import pika,sys
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
))
channel=connection.channel()
channel.queue_declare(queue='test1',durable=True) #durable=Ture, make queue persistent
msg=''.join(sys.argv[1:]) or 'Hello'
channel.basic_publish(
exchange='',
routing_key='test1',
body=msg,
properties=pika.BasicProperties(
delivery_mode=2 #make msg persisdent
)
)
print('Send done:',msg)
connection.close()
3.公平分发
在多consumer的情况下,默认rabbit是轮询发送消息的,但有的consumer消费速度快,有的消费速度慢,为了资源使用更平衡,引入ack确认机制。consumer消费完消息后会给rabbit发送ack,一旦未ack的消息数量超过指定允许的数量,则不再往该consumer发送,改为发送给其他consumer。
producer端代码不用改变,需要给consumer端代码插入两个属性:
channel.basic_qos(prefetch_count= *) #define the max non_ack_count channel.basic_ack(delivery_tag=deliver.delivery_tag) #send ack to rabbitmq
属性插入位置见如下代码(consumer端):
#Author :ywq
import pika,time
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
)
)
channel=connection.channel()
channel.queue_declare(queue='test2',durable=True)
def callback(chann,deliver,properties,body):
print('Recv:',body)
time.sleep(5)
chann.basic_ack(delivery_tag=deliver.delivery_tag) #send ack to rabbit
channel.basic_qos(prefetch_count=1)
'''
注意,no_ack=False 注意,这里的no_ack类型仅仅是告诉rabbit该消费者队列是否返回ack,若要返回ack,需要在callback内定义
prefetch_count=1,未ack的msg数量超过1个,则此consumer不再接受msg,此配置需写在channel.basic_consume上方,否则会造成non_ack情况出现。
'''
channel.basic_consume(
callback,
queue='test2'
)
channel.start_consuming()
三、消息发布/订阅
上方的几种模式都是producer端发送一次,则consumer端接收一次,能不能实现一个producer发送,多个关联的consumer同时接收呢?of course,rabbit支持消息发布订阅,共支持三种模式,通过组件exchange转发器,实现3种模式:

fanout: 所有bind到此exchange的queue都可以接收消息,类似广播。
direct: 通过routingKey和exchange决定的哪个唯一的queue可以接收消息,推送给绑定了该queue的consumer,类似组播。
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息,类似前缀列表匹配路由。
1.fanout
publish端(producer):
#Author :ywq
import pika,sys,time
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
)
)
channel=connection.channel()
channel.exchange_declare(exchange='hello',
exchange_type='fanout'
)
msg=''.join(sys.argv[1:]) or 'Hello world %s' %time.time()
channel.basic_publish(
exchange='hello',
routing_key='',
body=msg,
properties=pika.BasicProperties(
delivery_mode=2
)
)
print('send done')
connection.close()
subscribe端(consumer):
#Author :ywq
import pika
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
)
)
channel=connection.channel()
channel.exchange_declare(
exchange='hello',
exchange_type='fanout'
)
random_num=channel.queue_declare(exclusive=True) #随机与rabbit建立一个queue,comsumer断开后,该queue立即删除释放
queue_name=random_num.method.queue
channel.basic_qos(prefetch_count=1)
channel.queue_bind(
queue=queue_name,
exchange='hello'
)
def callback(chann,deliver,properties,body):
print('Recv:',body)
chann.basic_ack(delivery_tag=deliver.delivery_tag) #send ack to rabbit
channel.basic_consume(
callback,
queue=queue_name,
)
channel.start_consuming()
实现producer一次发送,多个关联consumer接收。
使用exchange模式时:
1.producer端不再申明queue,直接申明exchange
2.consumer端仍需绑定队列并指定exchange来接收message
3.consumer最好创建随机queue,使用完后立即释放。
随机队列名在web下可以检测到:

2.direct

使用exchange同时consumer有选择性的接收消息。队列绑定关键字,producer将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列,consumer相应接收。即在fanout基础上增加了routing key.
producer:
#Author :ywq
import pika,sys
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
)
)
channel=connection.channel()
channel.exchange_declare(exchange='direct_log',
exchange_type='direct',
)
while True:
route_key=input('Input routing key:')
msg=''.join(sys.argv[1:]) or 'Hello'
channel.basic_publish(
exchange='direct_log',
routing_key=route_key,
body=msg,
properties=pika.BasicProperties(
delivery_mode=2
)
)
connection.close()
consumer:
#Author :ywq
import pika,sys
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
))
channel=connection.channel()
channel.exchange_declare(
exchange='direct_log',
exchange_type='direct'
)
queue_num=channel.queue_declare(exclusive=True)
queue_name=queue_num.method.queue
route_key=input('Input routing key:')
channel.queue_bind(
queue=queue_name,
exchange='direct_log',
routing_key=route_key
)
def callback(chann,deliver,property,body):
print('Recv:[level:%s],[msg:%s]' %(route_key,body))
chann.basic_ack(delivery_tag=deliver.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
callback,
queue=queue_name
)
channel.start_consuming()
同时开启多个consumer,其中两个接收notice,两个接收warning,运行效果如下:

3.topic

相较于direct,topic能实现模糊匹配式工作方式(在consumer端指定匹配方式),只要routing key包含指定的关键字,则将该msg发往绑定的queue上。
rabbitmq通配符规则:
符号“#”匹配一个或多个词,符号“”匹配一个词。因此“abc.#”能够匹配到“abc.m.n”,但是“abc.*‘' 只会匹配到“abc.m”。‘.'号为分割符。使用通配符匹配时必须使用‘.'号分割。
producer:
#Author :ywq
import pika,sys
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
)
)
channel=connection.channel()
channel.exchange_declare(exchange='topic_log',
exchange_type='topic',
)
while True:
route_key=input('Input routing key:')
msg=''.join(sys.argv[1:]) or 'Hello'
channel.basic_publish(
exchange='topic_log',
routing_key=route_key,
body=msg,
properties=pika.BasicProperties(
delivery_mode=2
)
)
connection.close()
consumer:
#Author :ywq
import pika,sys
auth_info=pika.PlainCredentials('ywq','qwe')
connection=pika.BlockingConnection(pika.ConnectionParameters(
'192.168.0.158',5672,'/',auth_info
))
channel=connection.channel()
channel.exchange_declare(
exchange='topic_log',
exchange_type='topic'
)
queue_num=channel.queue_declare(exclusive=True)
queue_name=queue_num.method.queue
route_key=input('Input routing key:')
channel.queue_bind(
queue=queue_name,
exchange='topic_log',
routing_key=route_key
)
def callback(chann,deliver,property,body):
print('Recv:[type:%s],[msg:%s]' %(route_key,body))
chann.basic_ack(delivery_tag=deliver.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
callback,
queue=queue_name
)
channel.start_consuming()
运行效果:

rabbitmq三种publish/subscribe模型简单介绍完毕。
以上这篇python队列通信:rabbitMQ的使用(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。