Python中使用支持向量机(SVM)算法
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类(异常值检测)以及回归分析。
其具有以下特征:
(1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
(2) SVM通过最大化决策边界的边缘来实现控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
(3)SVM一般只能用在二类问题,对于多类问题效果不好。
1. 下面是代码及详细解释(基于sklearn包):
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
#准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1]
##开始训练
clf=svm.SVC() ##默认参数:kernel='rbf'
clf.fit(x,y)
#print("预测...")
#res=clf.predict([[2,2]]) ##两个方括号表面传入的参数是矩阵而不是list
##根据训练出的模型绘制样本点
for i in x:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
plt.scatter(i[0],i[1],c='r',marker='*')
else :
plt.scatter(i[0],i[1],c='g',marker='*')
##生成随机实验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2))
##回执实验数据点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
plt.scatter(i[0],i[1],c='r',marker='.')
else :
plt.scatter(i[0],i[1],c='g',marker='.')
##显示绘图结果
plt.show()
结果如下图:
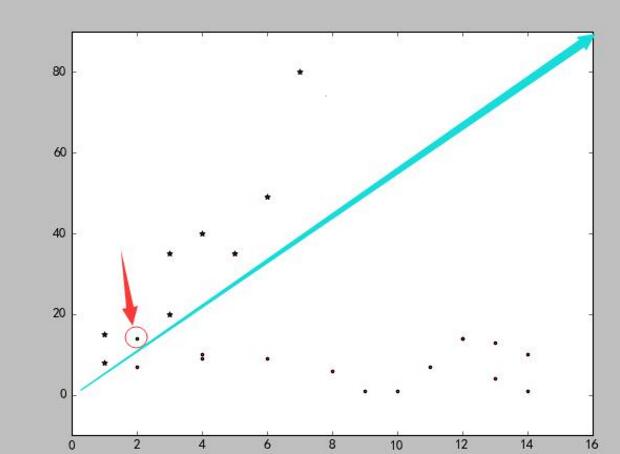
从图上可以看出,数据明显被蓝色分割线分成了两类。但是红色箭头标示的点例外,所以这也起到了检测异常值的作用。
2.在上面的代码中提到了kernel='rbf',这个参数是SVM的核心:核函数
重新整理后的代码如下:
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
##设置子图数量
fig, axes = plt.subplots(nrows=2, ncols=2,figsize=(7,7))
ax0, ax1, ax2, ax3 = axes.flatten()
#准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1]
'''
说明1:
核函数(这里简单介绍了sklearn中svm的四个核函数,还有precomputed及自定义的)
LinearSVC:主要用于线性可分的情形。参数少,速度快,对于一般数据,分类效果已经很理想
RBF:主要用于线性不可分的情形。参数多,分类结果非常依赖于参数
polynomial:多项式函数,degree 表示多项式的程度-----支持非线性分类
Sigmoid:在生物学中常见的S型的函数,也称为S型生长曲线
说明2:根据设置的参数不同,得出的分类结果及显示结果也会不同
'''
##设置子图的标题
titles = ['LinearSVC (linear kernel)',
'SVC with polynomial (degree 3) kernel',
'SVC with RBF kernel', ##这个是默认的
'SVC with Sigmoid kernel']
##生成随机试验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2))
def drawPoint(ax,clf,tn):
##绘制样本点
for i in x:
ax.set_title(titles[tn])
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='*')
else :
ax.scatter(i[0],i[1],c='g',marker='*')
##绘制实验点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='.')
else :
ax.scatter(i[0],i[1],c='g',marker='.')
if __name__=="__main__":
##选择核函数
for n in range(0,4):
if n==0:
clf = svm.SVC(kernel='linear').fit(x, y)
drawPoint(ax0,clf,0)
elif n==1:
clf = svm.SVC(kernel='poly', degree=3).fit(x, y)
drawPoint(ax1,clf,1)
elif n==2:
clf= svm.SVC(kernel='rbf').fit(x, y)
drawPoint(ax2,clf,2)
else :
clf= svm.SVC(kernel='sigmoid').fit(x, y)
drawPoint(ax3,clf,3)
plt.show()
结果如图:
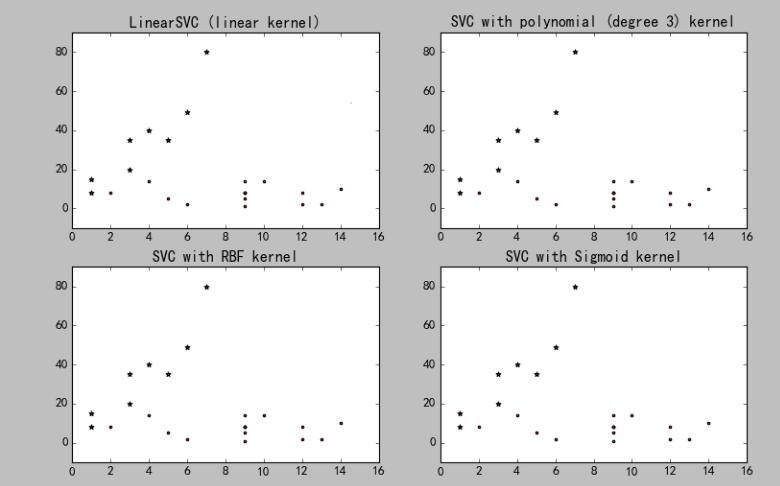
由于样本数据的关系,四个核函数得出的结果一致。在实际操作中,应该选择效果最好的核函数分析。
3.在svm模块中还有一个较为简单的线性分类函数:LinearSVC(),其不支持kernel参数,因为设计思想就是线性分类。如果确定数据
可以进行线性划分,可以选择此函数。跟kernel='linear'用法对比如下:
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
##设置子图数量
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(7,7))
ax0, ax1 = axes.flatten()
#准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1]
##设置子图的标题
titles = ['SVC (linear kernel)',
'LinearSVC']
##生成随机试验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2))
##画图函数
def drawPoint(ax,clf,tn):
##绘制样本点
for i in x:
ax.set_title(titles[tn])
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='*')
else :
ax.scatter(i[0],i[1],c='g',marker='*')
##绘制实验点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='.')
else :
ax.scatter(i[0],i[1],c='g',marker='.')
if __name__=="__main__":
##选择核函数
for n in range(0,2):
if n==0:
clf = svm.SVC(kernel='linear').fit(x, y)
drawPoint(ax0,clf,0)
else :
clf= svm.LinearSVC().fit(x, y)
drawPoint(ax1,clf,1)
plt.show()
结果如图所示:
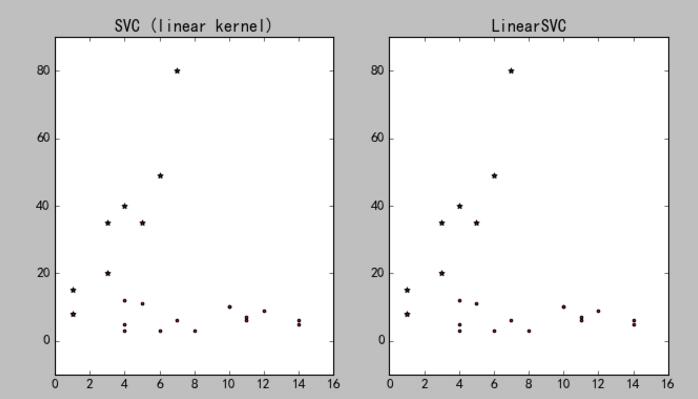
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。