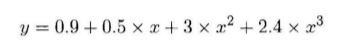Python登录并获取CSDN博客所有文章列表代码实例
分析登录过程
这几天研究百度登录和贴吧签到,这百度果然是互联网巨头,一个登录过程都弄得复杂无比,简直有毒。我研究了好几天仍然没搞明白。所以还是先挑一个软柿子捏捏,就选择CSDN了。
过程很简单,我也不截图了。直接打开浏览器,然后打开Fiddler,然后登录CSDN。然后Fiddler显示浏览器向https://passport.csdn.net/account/login?ref=toolbar发送了一个POST请求,这个请求包含了登录表单,而且还是未加密的。当然CSDN本身还是使用了HTTPS,所以安全性还行。
请求体如下,username和password当然是用户名和密码了。
username=XXXXX&password=XXXXXX&rememberMe=true<=LT-461600-wEKpWAqbfZoULXmFmDIulKPbL44hAu&execution=e4s1&_eventId=submit
lt参数我不知道是干啥的,结果直接在页面中一看原来全在表单里头,这下直接全了。CSDN很贴心的连注释都给出了。另外如果你打开百度首页的话,还会发现浏览器的log中还会输出百度的招聘信息。

HTML截图
登录代码
这些信息全有了,这样我们就可以登录了。不说废话,直接上代码。先说说我遇到的几个坑。
首先是一个参数错误,其实逻辑没问题,但是代码我复制粘贴之后忘了改名字了,就登录表单那里,三个参数全弄成了lt,结果登录返回来的页面是错误页面。我还以为是没有附带什么请求头,瞎整了大半天。最后用Fiddler调试了好多遍才发现。
第二个问题就是CSDN鸡贼的跳转。由于浏览器自带了JS引擎,所以我们在浏览器中输入网址,到达页面这一过程不一定就是一个请求。可能中间用了什么JS代码先跳转到中间页面,最后才跳转到实际页面。代码里的_validate_redirect_url(self)函数就是干这个的,登录完了第一次请求会得到一个中间页面,它包含了一堆JS代码,其中有个重定向网址。我们获取到这个重定向网址,还得请求一次,获得200OK之后,后续请求才能获得实际页面。
第三个问题就是正则表达式匹配页面的空格问题了。获取文章首先得知道文章总数,这个好办,直接获取页面里的文章数就行了。它类似100条共20页这个。那么该怎么获取呢?一开始我用的(\d+)条共(\d+)页这个正则,但是结果没匹配到,然后我仔细看了一下页面,原来这两个词之间不是一个空格,而是两个空格!其实这个问题倒是也好办,改一下正则(\d+)条\s*共(\d+)页就行了。所以以后如果遇到空格问题,直接用\s匹配,不要想着自己输入一个空格还是两个空格。
import requests
from bs4 import BeautifulSoup
import re
import urllib.parse as parse
class CsdnHelper:
"""登录CSDN和列出所有文章的类"""
csdn_login_url = 'https://passport.csdn.net/account/login?ref=toolbar'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
}
blog_url = 'http://write.blog.csdn.net/postlist/'
def __init__(self):
self._session = requests.session()
self._session.headers = CsdnHelper.headers
def login(self, username, password):
'''登录主函数'''
form_data = self._prepare_login_form_data(username, password)
response = self._session.post(CsdnHelper.csdn_login_url, data=form_data)
if 'UserNick' in response.cookies:
nick = response.cookies['UserNick']
print(parse.unquote(nick))
else:
raise Exception('登录失败')
def _prepare_login_form_data(self, username, password):
'''从页面获取参数,准备提交表单'''
response = self._session.get(CsdnHelper.csdn_login_url)
login_page = BeautifulSoup(response.text, 'lxml')
login_form = login_page.find('form', id='fm1')
lt = login_form.find('input', attrs={'name': 'lt'})['value']
execution = login_form.find('input', attrs={'name': 'execution'})['value']
eventId = login_form.find('input', attrs={'name': '_eventId'})['value']
form = {
'username': username,
'password': password,
'lt': lt,
'execution': execution,
'_eventId': eventId
}
return form
def _get_blog_count(self):
'''获取文章数和页数'''
self._validate_redirect_url()
response = self._session.get(CsdnHelper.blog_url)
blog_page = BeautifulSoup(response.text, 'lxml')
span = blog_page.find('div', class_='page_nav').span
print(span.string)
pattern = re.compile(r'(\d+)条\s*共(\d+)页')
result = pattern.findall(span.string)
blog_count = int(result[0][0])
page_count = int(result[0][1])
return (blog_count, page_count)
def _validate_redirect_url(self):
'''验证重定向网页'''
response = self._session.get(CsdnHelper.blog_url)
redirect_url = re.findall(r'var redirect = "(\S+)";', response.text)[0]
self._session.get(redirect_url)
def print_blogs(self):
'''输出文章信息'''
blog_count, page_count = self._get_blog_count()
for index in range(1, page_count + 1):
url = f'http://write.blog.csdn.net/postlist/0/0/enabled/{index}'
response = self._session.get(url)
page = BeautifulSoup(response.text, 'lxml')
links = page.find_all('a', href=re.compile(r'http://blog.csdn.net/u011054333/article/details/(\d+)'))
print(f'----------第{index}页----------')
for link in links:
blog_name = link.string
blog_url = link['href']
print(f'文章名称:《{blog_name}》 文章链接:{blog_url}')
if __name__ == '__main__':
csdn_helper = CsdnHelper()
username = input("请输入用户名")
password = input("请输入密码")
csdn_helper.login(username, password)
csdn_helper.print_blogs()
当然,这里最重要的的就是登录过程了。我们登录之后,才可以做其他事情。比方说,下一步还能写一个备份工具,把CSDN博客的所有文章和图片下载到本地。有兴趣的同学可以试一试。
总结
以上就是本文关于Python登录并获取CSDN博客所有文章列表代码实例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!