解决python使用open打开文件中文乱码的问题
代码如下:
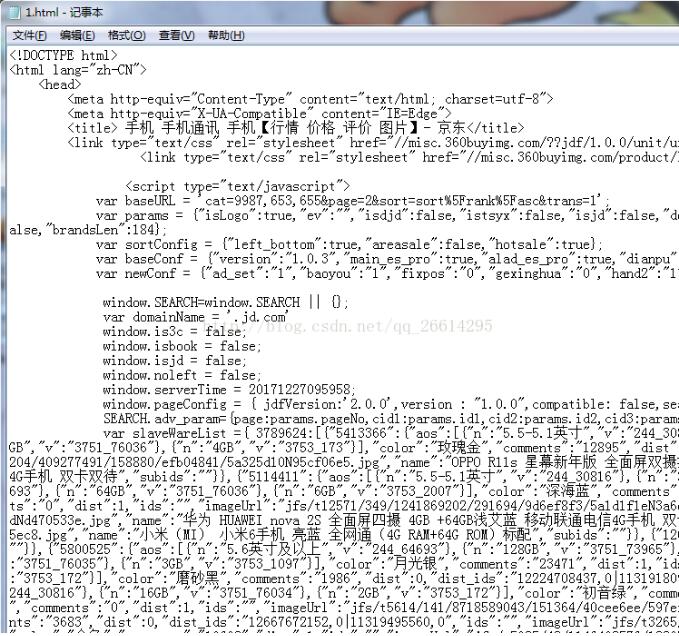
先在D盘下新建一个html文档,然后在里面输入含有中文的Html字符如下图,然后我们首先使用中文格式对读取的字符进行解码再用utf-8的模式对字符进行进行编码,然后就能正确输出中文字符
# -*- coding: UTF-8 -*-
file1 = open("D:/1.html", mode='rb+')
data = file1.read().decode('gbk').encode('utf-8')
print data
以上这篇解决python使用open打开文件中文乱码的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。