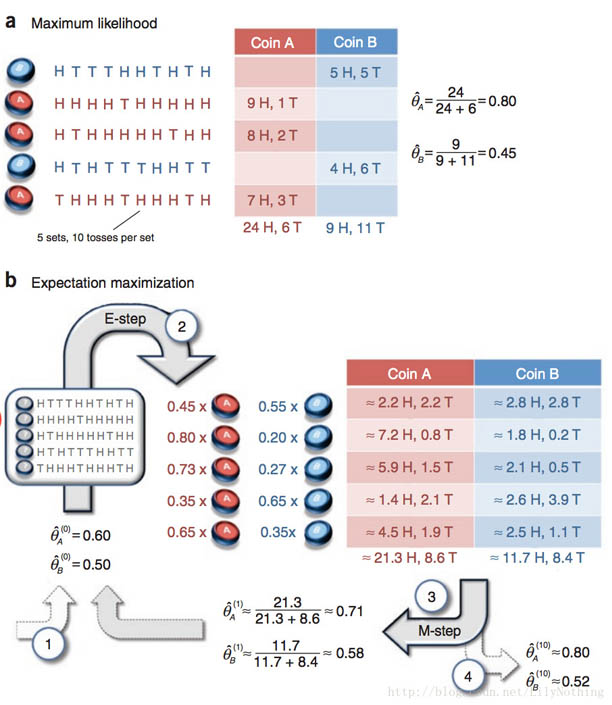
python机器学习理论与实战(五)支持向量机
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子。他的理论很优美,各种变种改进版本也很多,比如latent-SVM, structural-SVM等。这节先来看看SVM的理论吧,在(图一)中A图表示有两类的数据集,图B,C,D都提供了一个线性分类器来对数据进行分类?但是哪个效果好一些?
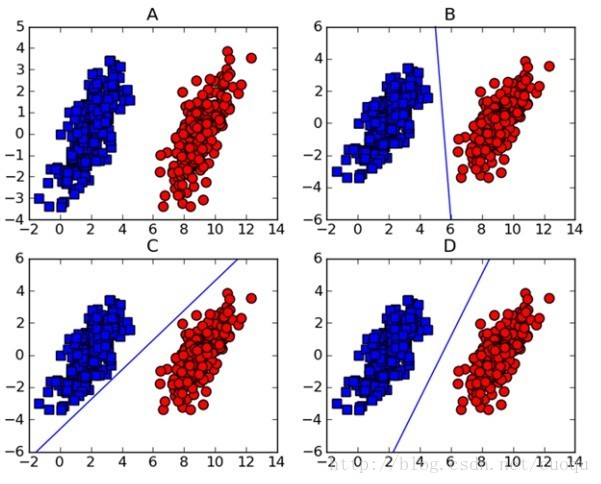
(图一)
可能对这个数据集来说,三个的分类器都一样足够好了吧,但是其实不然,这个只是训练集,现实测试的样本分布可能会比较散一些,各种可能都有,为了应对这种情况,我们要做的就是尽可能的使得线性分类器离两个数据集都尽可能的远,因为这样就会减少现实测试样本越过分类器的风险,提高检测精度。这种使得数据集到分类器之间的间距(margin)最大化的思想就是支持向量机的核心思想,而离分类器距离最近的样本成为支持向量。既然知道了我们的目标就是为了寻找最大边距,怎么寻找支持向量?如何实现?下面以(图二)来说明如何完成这些工作。
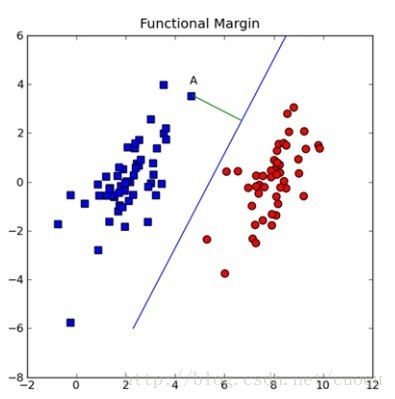
(图二)
假设(图二)中的直线表示一个超面,为了方面观看显示成一维直线,特征都是超面维度加一维度的,图中也可以看出,特征是二维,而分类器是一维的。如果特征是三维的,分类器就是一个平面。假设超面的解析式为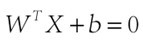 ,那么点A到超面的距离为
,那么点A到超面的距离为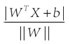 ,下面给出这个距离证明:
,下面给出这个距离证明:

(图三)
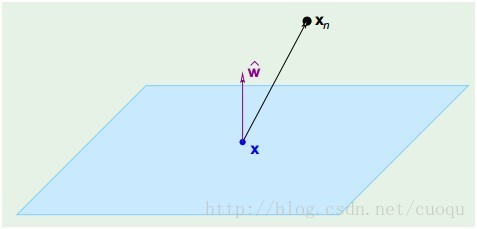
在(图三)中,青色菱形表示超面,Xn为数据集中一点,W是超面权重,而且W是垂直于超面的。证明垂直很简单,假设X'和X''都是超面上的一点,

因此W垂直于超面。知道了W垂直于超面,那么Xn到超面的距离其实就是Xn和超面上任意一点x的连线在W上的投影,如(图四)所示:
套进拉格朗日乘子法公式得到如(公式五)所示的样子:
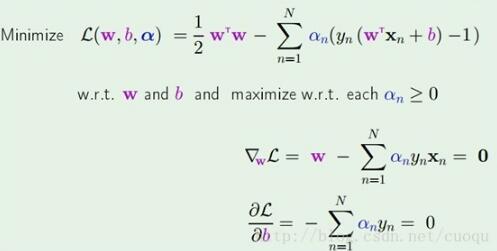
(公式五)
在(公式五)中通过拉格朗日乘子法函数分别对W和b求导,为了得到极值点,令导数为0,得到

,然后把他们代入拉格朗日乘子法公式里得到(公式六)的形式:
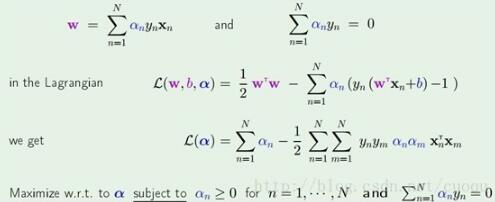
(公式六)
(公式六)后两行是目前我们要求解的优化函数,现在只需要做个二次规划即可求出alpha,二次规划优化求解如(公式七)所示:

(公式七)
通过(公式七)求出alpha后,就可以用(公式六)中的第一行求出W。到此为止,SVM的公式推导基本完成了,可以看出数学理论很严密,很优美,尽管有些同行们认为看起枯燥,但是最好沉下心来从头看完,也不难,难的是优化。二次规划求解计算量很大,在实际应用中常用SMO(Sequential minimal optimization)算法,SMO算法打算放在下节结合代码来说。
参考文献:
[1]machine learning in action. Peter Harrington
[2] Learning From Data. Yaser S.Abu-Mostafa
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。