python机器学习理论与实战(一)K近邻法
机器学习分两大类,有监督学习(supervised learning)和无监督学习(unsupervised learning)。有监督学习又可分两类:分类(classification.)和回归(regression),分类的任务就是把一个样本划为某个已知类别,每个样本的类别信息在训练时需要给定,比如人脸识别、行为识别、目标检测等都属于分类。回归的任务则是预测一个数值,比如给定房屋市场的数据(面积,位置等样本信息)来预测房价走势。而无监督学习也可以成两类:聚类(clustering)和密度估计(density estimation),聚类则是把一堆数据聚成弱干组,没有类别信息;密度估计则是估计一堆数据的统计参数信息来描述数据,比如深度学习的RBM。
根据机器学习实战讲解顺序,先学习K近邻法(K Nearest Neighbors-KNN)
K近邻法是有监督学习方法,原理很简单,假设我们有一堆分好类的样本数据,分好类表示每个样本都一个对应的已知类标签,当来一个测试样本要我们判断它的类别是,就分别计算到每个样本的距离,然后选取离测试样本最近的前K个样本的标签累计投票,得票数最多的那个标签就为测试样本的标签。
例子(电影分类):

(图一)
(图一)中横坐标表示一部电影中的打斗统计个数,纵坐标表示接吻次数。我们要对(图一)中的问号这部电影进行分类,其他几部电影的统计数据和类别如(图二)所示:
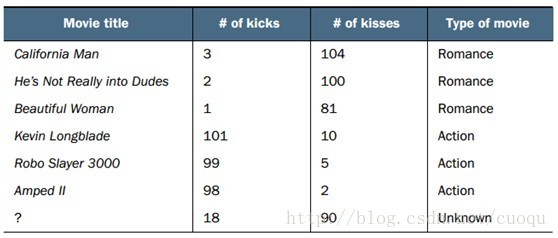
(图二)
从(图二)中可以看出有三部电影的类别是Romance,有三部电影的类别是Action,那如何判断问号表示的这部电影的类别?根据KNN原理,我们需要在(图一)所示的坐标系中计算问号到所有其他电影之间的距离。计算出的欧式距离如(图三)所示:
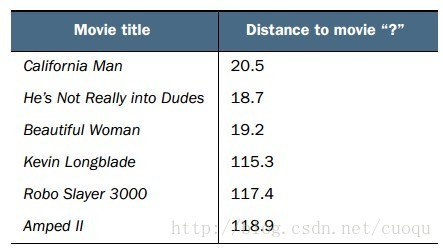
(图三)
由于我们的标签只有两类,那假设我们选K=6/2=3,由于前三个距离最近的电影都是Romance,那么问号表示的电影被判定为Romance。
代码实战(Python版本):
先来看看KNN的实现:
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #获取一条样本大小
diffMat = tile(inX, (dataSetSize,1)) - dataSet #计算距离
sqDiffMat = diffMat**2 #计算距离
sqDistances = sqDiffMat.sum(axis=1) #计算距离
distances = sqDistances**0.5 #计算距离
sortedDistIndicies = distances.argsort() #距离排序
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] #前K个距离最近的投票统计
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #前K个距离最近的投票统计
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #对投票统计进行排序
return sortedClassCount[0][0] #返回最高投票的类别
下面取一些样本测试KNN:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.50 #hold out 50%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
上面的代码中第一个函数从文本文件中读取样本数据,第二个函数把样本归一化,归一化的好处就是降低样本不同特征之间数值量级对距离计算的显著性影响
datingClassTest则是对KNN测试,留了一半数据进行测试,文本文件中的每条数据都有标签,这样可以计算错误率,运行的错误率为:the total error rate is: 0.064000
总结:
优点:高精度,对离群点不敏感,对数据不需要假设模型
缺点:判定时计算量太大,需要大量的内存
工作方式:数值或者类别
下面挑选一步样本数据发出来:
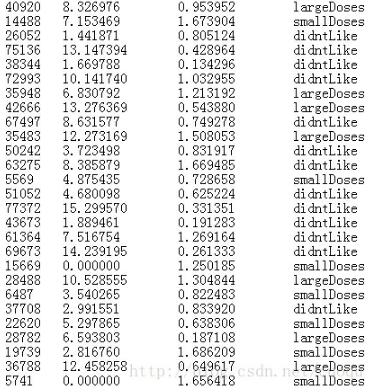
参考文献:machine learning in action
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。