用tensorflow搭建CNN的方法
CNN(Convolutional Neural Networks) 卷积神经网络简单讲就是把一个图片的数据传递给CNN,原涂层是由RGB组成,然后CNN把它的厚度加厚,长宽变小,每做一层都这样被拉长,最后形成一个分类器
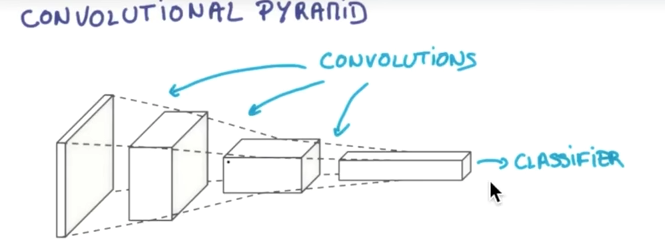
在 CNN 中有几个重要的概念:
- stride
- padding
- pooling
stride,就是每跨多少步抽取信息。每一块抽取一部分信息,长宽就缩减,但是厚度增加。抽取的各个小块儿,再把它们合并起来,就变成一个压缩后的立方体。
padding,抽取的方式有两种,一种是抽取后的长和宽缩减,另一种是抽取后的长和宽和原来的一样。
pooling,就是当跨步比较大的时候,它会漏掉一些重要的信息,为了解决这样的问题,就加上一层叫pooling,事先把这些必要的信息存储起来,然后再变成压缩后的层
利用tensorflow搭建CNN,也就是卷积神经网络是一件很简单的事情,笔者按照官方教程中使用MNIST手写数字识别为例展开代码,整个程序也基本与官方例程一致,不过在比较容易迷惑的地方加入了注释,有一定的机器学习或者卷积神经网络制式的人都应该可以迅速领会到代码的含义。
#encoding=utf-8
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1) #截断正态分布,此函数原型为尺寸、均值、标准差
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') # strides第0位和第3为一定为1,剩下的是卷积的横向和纵向步长
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize = [1,2,2,1],strides=[1,2,2,1],padding='SAME')# 参数同上,ksize是池化块的大小
x = tf.placeholder("float", shape=[None, 784])
y_ = tf.placeholder("float", shape=[None, 10])
# 图像转化为一个四维张量,第一个参数代表样本数量,-1表示不定,第二三参数代表图像尺寸,最后一个参数代表图像通道数
x_image = tf.reshape(x,[-1,28,28,1])
# 第一层卷积加池化
w_conv1 = weight_variable([5,5,1,32]) # 第一二参数值得卷积核尺寸大小,即patch,第三个参数是图像通道数,第四个参数是卷积核的数目,代表会出现多少个卷积特征
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,w_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层卷积加池化
w_conv2 = weight_variable([5,5,32,64]) # 多通道卷积,卷积出64个特征
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 原图像尺寸28*28,第一轮图像缩小为14*14,共有32张,第二轮后图像缩小为7*7,共有64张
w_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64]) # 展开,第一个参数为样本数量,-1未知
f_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)
# dropout操作,减少过拟合
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(f_fc1,keep_prob)
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,w_fc2)+b_fc2)
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) # 定义交叉熵为loss函数
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 调用优化器优化
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for i in range(2000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images[0:500], y_: mnist.test.labels[0:500], keep_prob: 1.0})
在程序中主要注意这么几点:
1、维度问题,由于我们tensorflow基于的是张量这样一个概念,张量其实就是维度扩展的矩阵,因此维度特别重要,而且维度也是很容易使人迷惑的地方。
2、卷积问题,卷积核不只是二维的,多通道卷积时卷积核就是三维的
3、最后进行检验的时候,如果一次性加载出所有的验证集,出现了内存爆掉的情况,由于是使用的是云端的服务器,可能内存小一些,如果内存够用可以直接全部加载上看结果
4、这个程序原始版本迭代次数设置了20000次,这个次数大约要训练数个小时(在不使用GPU的情况下),这个次数可以按照要求更改。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。