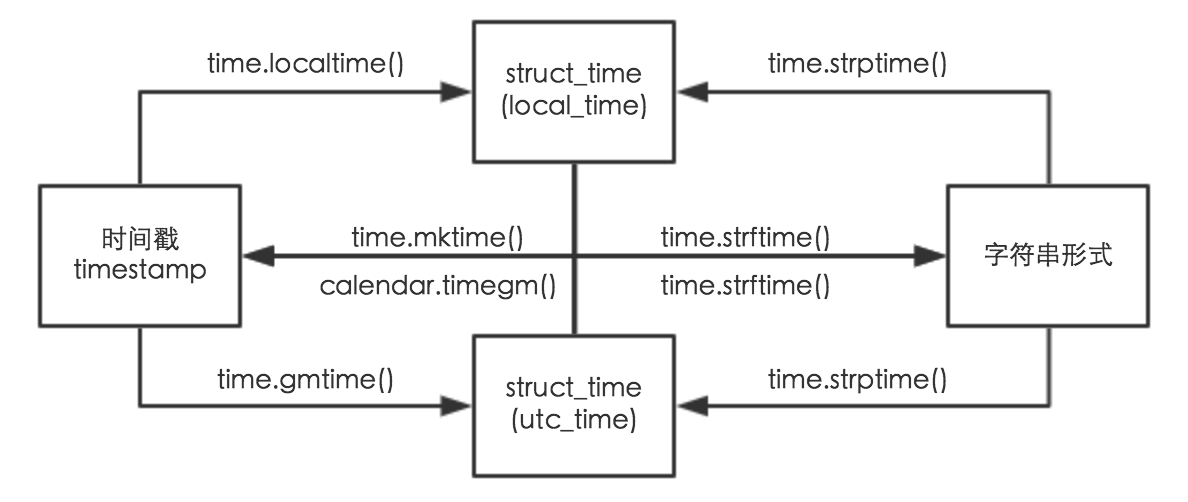
python文本数据相似度的度量
编辑距离
编辑距离,又称为Levenshtein距离,是用于计算一个字符串转换为另一个字符串时,插入、删除和替换的次数。例如,将'dad'转换为'bad'需要一次替换操作,编辑距离为1。
nltk.metrics.distance.edit_distance函数实现了编辑距离。
from nltk.metrics.distance import edit_distance str1 = 'bad' str2 = 'dad' print(edit_distance(str1, str2))
N元语法相似度
n元语法只是简单地表示文本中n个标记的所有可能的连续序列。n元语法具体是这样的
import nltk
#这里展示2元语法
text1 = 'Chief Executive Officer'
#bigram考虑匹配开头和结束,所有使用pad_right和pad_left
ceo_bigrams = nltk.bigrams(text1.split(),pad_right=True,pad_left=True)
print(list(ceo_bigrams))
[(None, 'Chief'), ('Chief', 'Executive'),
('Executive', 'Officer'), ('Officer', None)]
2元语法相似度计算
import nltk #这里展示2元语法 def bigram_distance(text1, text2): #bigram考虑匹配开头和结束,所以使用pad_right和pad_left text1_bigrams = nltk.bigrams(text1.split(),pad_right=True,pad_left=True) text2_bigrams = nltk.bigrams(text2.split(), pad_right=True, pad_left=True) #交集的长度 distance = len(set(text1_bigrams).intersection(set(text2_bigrams))) return distance text1 = 'Chief Executive Officer is manager' text2 = 'Chief Technology Officer is technology manager' print(bigram_distance(text1, text2)) #相似度为3
jaccard相似性
jaccard距离度量的两个集合的相似度,它是由 (集合1交集合2)/(结合1交结合2)计算而来的。
实现方式
from nltk.metrics.distance import jaccard_distance #这里我们以单个的字符代表文本 set1 = set(['a','b','c','d','a']) set2 = set(['a','b','e','g','a']) print(jaccard_distance(set1, set2))
0.6666666666666666
masi距离
masi距离度量是jaccard相似度的加权版本,当集合之间存在部分重叠时,通过调整得分来生成小于jaccard距离值。
from nltk.metrics.distance import jaccard_distance,masi_distance #这里我们以单个的字符代表文本 set1 = set(['a','b','c','d','a']) set2 = set(['a','b','e','g','a']) print(jaccard_distance(set1, set2)) print(masi_distance(set1, set2))
0.6666666666666666
0.22000000000000003
余弦相似度
nltk提供了余弦相似性的实现方法,比如有一个词语空间
word_space = [w1,w2,w3,w4] text1 = 'w1 w2 w1 w4 w1' text2 = 'w1 w3 w2' #按照word_space位置,计算每个位置词语出现的次数 text1_vector = [3,1,0,1] text2_vector = [1,1,1,0]
[3,1,0,1]意思是指w1出现了3次,w2出现了1次,w3出现0次,w4出现1次。
好了下面看代码,计算text1与text2的余弦相似性
from nltk.cluster.util import cosine_distance text1_vector = [3,1,0,1] text2_vector = [1,1,1,0] print(cosine_distance(text1_vector,text2_vector))
0.303689376177
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。