特征脸(Eigenface)理论基础之PCA主成分分析法
在之前的博客 人脸识别经典算法一:特征脸方法(Eigenface)里面介绍了特征脸方法的原理,但是并没有对它用到的理论基础PCA做介绍,现在做补充。请将这两篇博文结合起来阅读。以下内容大部分参考自斯坦福机器学习课程:http://cs229.stanford.edu/materials.html
假设我们有一个关于机动车属性的数据集{x(i);i=1,...,m}(m代表机动车的属性个数),例如最大速度,最大转弯半径等。假设x(i)本质上是n维的空间的一个元素,其中n<<m,但是n对我们来说是未知的。假设xi和xj分别代表车以英里和公里为单位的最大速度。显然这两个属性是冗余的,因为它们两个是有线性关系而且可以相互转化的。因此如果仅以xi和xj来考虑的话,这个数据集是属于m-1维而不是m维空间的,所以n=m-1。推广之,我们该用什么方法降低数据冗余性呢?
首先考虑一个例子,假设有一份对遥控直升机操作员的调查,用x(i)1(1是下标,原谅我这操蛋的排版吧)表示飞行员i的飞行技能,x(i)2表示飞行员i喜欢飞行的程度。通常遥控直升飞机是很难操作的,只有那些非常坚持而且真正喜欢驾驶的人才能熟练操作。所以这两个属性x(i)1和x(i)2相关性是非常强的。我们可以假设两者的关系是按正比关系变化的,如下图里的u1所示,数据散布在u1两侧是因为有少许噪声。
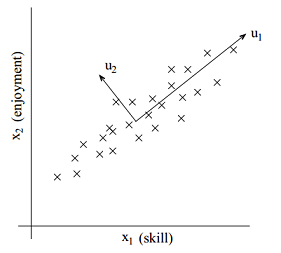
接下来就是如何计算u1的方向了。首先我们需要预处理数据。
1.令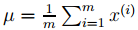
2.用x(i)-μ替代x(i)
3.求![]()
4.用x(i)j/σj替代x(i)j
步骤1-2其实是将数据集的均值归零,也就是只取数据的偏差部分,对于本身均值为零的数据可以忽略这两步。步骤3-4是按照每个属性的方差将数据重新度量,也可以理解为归一化。因为对于不同的属性(比如车的速度和车座数目)如果不归一化是不具有比较性的,两者不在一个量级上。如果将pca应用到图像上的话是不需要步骤3-4的,因为每个像素(相当于不同的属性)的取值范围都是一样的。
数据经过如上处理之后,接下来就是寻找数据大致的走向了。一种方法是找到一个单位向量u,使所有数据在u上的投影之和最大,当然数据并不是严格按照u的方向分布的,而是分布在其周围。考虑下图的数据分布(这些数据已经做了前期的预处理)。
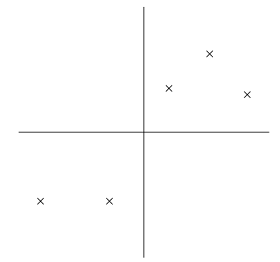
下图中,星号代表数据,原点代表数据在单位向量u上的投影(|x||u|cosΘ)
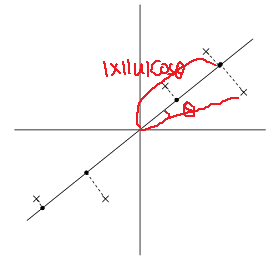
从上图可以看到,投影得到的数据仍然有很大的方差,而且投影点离原点很远。如果采取与上图u垂直的方向,则可以得到下图:

这里得到的投影方差比较小,而且离原点也更近。
上述u的方向只是感性的选择出来的,为了将选择u的步骤正式确定下来,可以假定在给定单位向量u和数据点x的情况下,投影的长度是xTu。举个例子,如果x(i)是数据集中的一个点(上图中的一个星号),那它在u上的投影xTu就是圆点到原点的距离(是标量哦)。所以,为了最大化投影的方差,我们需要选择一个单位向量u来最大化下式:
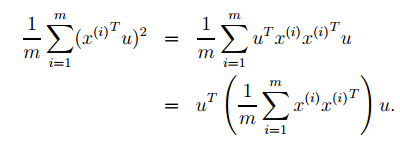
明显,按照||u||2=1(确保u是单位向量)来最大化上式就是求 的主特征向量。而其实是数据集的协方差矩阵。
的主特征向量。而其实是数据集的协方差矩阵。
做个总结,如果我们要找数据集分布的一维子空间(就是将m维的数据用一维数据来表示),我们要选择协方差矩阵的主特征向量。推广之,如果要找k维的子空间,那就应该选择协方差矩阵的k个特征向量u1,u2,...,uk。ui(i=1,2,...,k)就是用来表征数据集的新坐标系。
为了在u1,u2,...,uk的基础上表示x(i),我们只需要计算
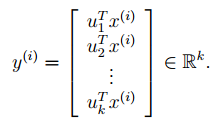
其中x(i)是属于n维空间的向量,而y(i)给出了基于k维空间的表示。因此说,PCA是一个数据降维算法。u1,u2,...,uk称为数据的k个主成分。
介绍到这里,还需要注意一些为题:
1、为什么u要选择单位向量
选择单位向量是为了统一表示数据,不选成单位的也可以,但各个向量长度必须统一,比如统一长度为2、3等等。
2、各个u要相互正交
如果u不正交,那么在各个u上的投影将含有冗余成分
2、为什么要最大化投影的方差
举个例子,如果在某个u上的投影方差为0,那这个u显然无法表示原数据,降维就没有意义了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。