Python读取Word(.docx)正文信息的方法
本文介绍用Python简单读取*.docx文件信息,一些python-word库就是对这种方法的扩展。
介绍分两部分:
- Word(*.docx)文件简述
- Python提取Word信息
Word(*.docx)文件简述
大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容。
为了跟上时代,微软采用类XML格式标准定义其新版Word文件.docx。
.docx实际上是一个zip的压缩文件,比如我们有一个test.docx的文件:

其内容如下:
改变其后缀名为test.zip,然后解压,会得到如下文件:
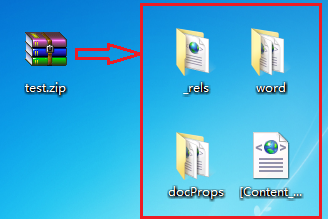
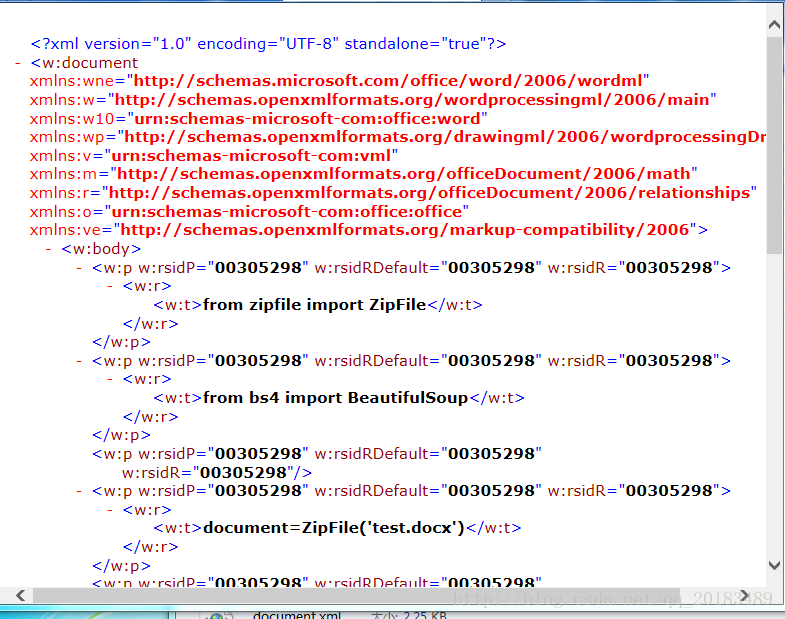
其中Word文件的正文内容被保持在word/document.xml中,我们可以打开查看:
Python提取Word信息
根据Word(.docx)文件格式,我们遵循如下步骤进行正文信息的提取:
1 解压.docx文件
2 用BeautifulSoup解析word/document.xml提取正文信息
具体代码如下:
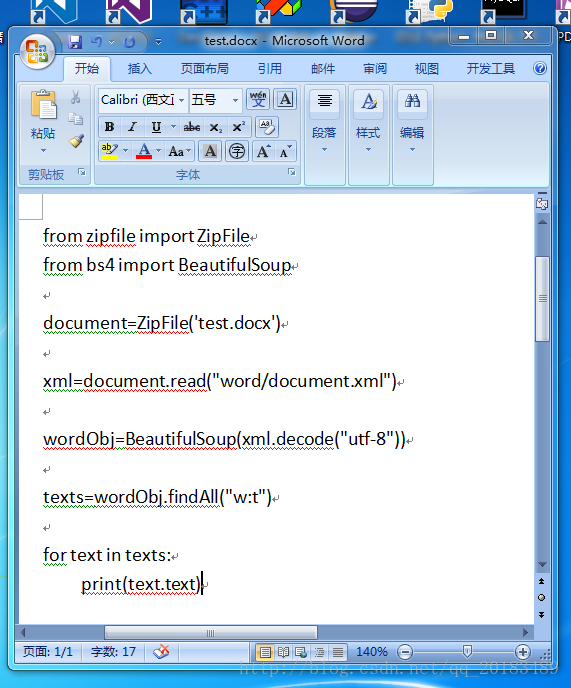
from zipfile import ZipFile
from bs4 import BeautifulSoup
document=ZipFile('test.docx')
xml=document.read("word/document.xml")
wordObj=BeautifulSoup(xml.decode("utf-8"))
texts=wordObj.findAll("w:t")
for text in texts:
print(text.text)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。