pandas系列之DataFrame 行列数据筛选实例
一、对DataFrame的认知
DataFrame的本质是行(index)列(column)索引+多列数据。
为了简化理解,我们不妨换个思路…
现实中,为了简化对一件事物的描述,我们会选择几个特征。
例如,从(性别、身高、学历、职业、爱好..)等角度去刻画一个人,这些“角度”即为“特征”。
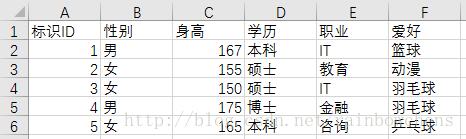
其中,不同的行表示不同的记录;列代表特征,不同记录因各个特征之间的差异而不同。
DataFrame默认索引是序号(0,1,2…),可以理解成位置索引。一般我们用id标识不同记录,不会改变index。但为了理解不同特征(列)含义,我们往往会重新指定column。
一些简易但不算严谨的理解是:
行列
行 – index – 记录 (一般沿用默认索引)
列 – column – 特征 (自定义索引)
索引
默认索引 – 序号 – 位置 – 方便索引但理解不易
自定义索引 – 特征名称 – 属性 – 便于理解
二、对dataframe进行行列数据筛选
import pandas as pd,numpy as np
from pandas import DataFrame
df = DataFrame(np.arange(20).reshape((4,5)),column = list('abcde'))

1.df[]&df. 选取列数据
df.a df[[‘a','b']]
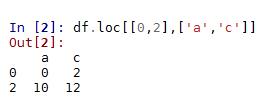
2.df.loc[[index],[colunm]] 通过标签选择数据
不对行进行筛选时,[index]处填 : (不能为空),即df.loc[:,'a']表示选取a列全部数据。
df.loc[0,'a'] df.loc[0:1,[‘a','b']] df.loc[[0,2],[‘a','c']]
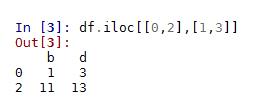
3.df.iloc[[index],[colunm]] 通过位置选择数据
不对行进行筛选时,同df.loc[],即[index]处不能为空。
df.iloc[0,0] df.iloc[0:1,1:3] df.iloc[[0,2],[1,3]]
4.df.ix[[index],[column]] 通过标签or位置选择数据
df.ix[]混合了标签和位置选择。需要注意的是,[index]和[column]的框内需要指定同一类的选择。
df.ix[[0:1],[‘a',3]]报错
以上这篇pandas系列之DataFrame 行列数据筛选实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。