Python在groupby分组后提取指定位置记录方法
在进行数据分析、数据建模时,我们首先要做的就是对数据进行处理,提取我们需要的信息。下面为大家介绍一些groupby的用法,以便能够更加方便地进行数据处理。
我们往往在使用groupby进行信息提取时,往往是求分组后样本的一些统计量(max、min,var等)。如果现在我们希望取一下分组后样本的第二条记录,倒数第三条记录,这个该如何操作呢?我们可以通过first、last来提取分组后第一条和最后一条样本。但如果我们要取指定位置的样本,就没有现成的函数。需要我们自己去写了。下面我就为大家介绍如何实现上面的功能。
1)数据介绍
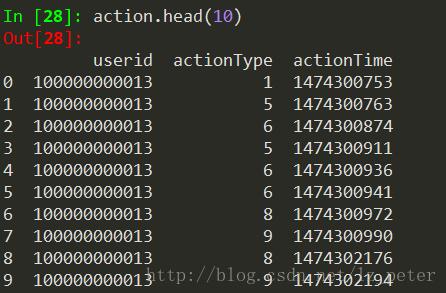
action表共有3列:userid、actionType和actionTime,分别代表用户id,用户行为类型和行为发生时间。具体格式如下图所示:
2)分组操作
a = action.groupby('userid')
b = action.groupby('userid')['actionTime']
type(a)
type(b)
分组后我们可以看到a和b的数据类型是DataFrameGroupBy和SeriesGroupBy

3)取数操作
①不同用户第二次/倒数第二次操作时间
action.groupby('userid')['actionTime'].apply(lambda i:i.iloc[1] if len(i)>1 else np.nan)
action.groupby('userid')['actionTime'].apply(lambda i:i.iloc[-2] if len(i)>1 else np.nan)
②不同用户某种行为第二次/倒数第二次操作时间
action[action['actionType']==2].groupby('userid')['actionTime'].apply(lambda i:i.iloc[1] if len(i)>1 else np.nan)
action[action['actionType']==2].groupby('userid')['actionTime'].apply(lambda i:i.iloc[-2] if len(i)>1 else np.nan)
PS:因为有些用户可能只有一条记录,直接取可能会出错,所以我用if先做判断。
这样我们就可以提取分组后数据任意位置的样本了。
以上这篇Python在groupby分组后提取指定位置记录方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。