Python 将pdf转成图片的方法
本篇文章记录如何使用python将pdf文件切分成一张一张图片,包括环境配置、版本兼容问题。
环境配置(mac)
安装ImageMagick
brew install imagemagick
这里有个坑,brew安装都是7.x版本,使用wand时会出错,需要你安装6.x版本。
解决办法:
1.安装6.x版本
brew install imagemagick@6
2.取消链接7.x版本
brew unlink imagemagick Unlinking /usr/local/Cellar/imagemagick/7.0.7-4… 71 symlinks removed
3.强制链接6.x版本
brew link imagemagick@6 --force Linking /usr/local/Cellar/imagemagick@6/6.9.9-15… 75 symlinks created
4.export环境变量
echo 'export PATH="/usr/local/opt/imagemagick@6/bin:$PATH"' >> ~/.bash_profile
ok,以上解决imagemagick版本问题。
安装gs
必须安装gs,否则pdf无法转换。
brew install gs
安装wand
pip3 install wand
我这里使用的是python3,所以需要用pip3.
代码实现
from wand.image import Image
def convert_pdf_to_jpg(filename):
with Image(filename=filename) as img :
print('pages = ', len(img.sequence))
with img.convert('jpeg') as converted:
converted.save(filename='image/page.jpeg')
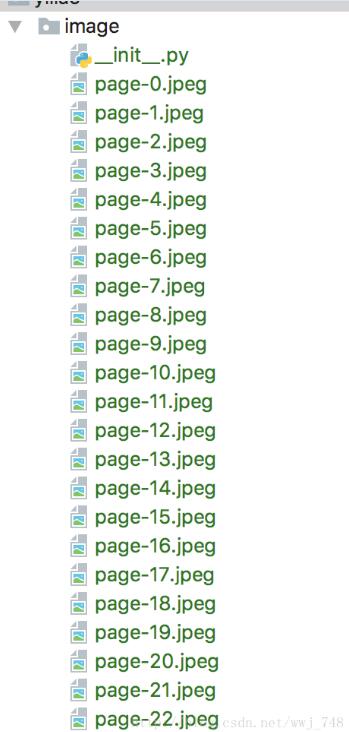
效果
笔者将一本书四百多页都转出来了,大家也可以去试下啦。
以上这篇Python 将pdf转成图片的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。