相关文章
wxpython绘制圆角窗体
本文实例为大家分享了wxpython绘制圆角窗体的具体代码,供大家参考,具体内容如下 # -*- coding:gbk -*- import wx class RCDialo...
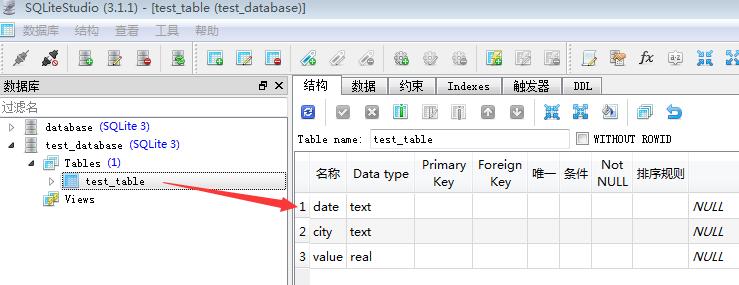
Python读取和处理文件后缀为.sqlite的数据文件(实例讲解)
最近在弄一个项目分析的时候,看到有一个后缀为”.sqlite”的数据文件,由于以前没怎么接触过,就想着怎么用python来打开并进行数据分析与处理,于是稍微研究了一下。 SQLite是一...
详解Django中的权限和组以及消息
在认证框架中还有其他的一些功能。 我们会在接下来的几个部分中进一步地了解它们。 权限 权限可以很方便地标识用户和用户组可以执行的操作。 它们被Django的admin管理站点所使用,你也...

Python3操作SQL Server数据库(实例讲解)
1.前言 前面学完了SQL Server的基本语法,接下来学习如何在程序中使用sql,毕竟不能在程序中使用的话,实用性就不那么大了。 2.最基本的SQL查询语句 python是使用pym...
python2.7的flask框架之引用js&css等静态文件的实现方法
动态 web 应用也会需要静态文件,通常是 CSS 和 JavaScript 文件。理想状况下, 我们已经配置好 Web 服务器来提供静态文件,但是在开发中,Flask 也可以做到。 只...