pandas.loc 选取指定列进行操作的实例
今天发现用pandas里面的数据结构可以减少大量的编程工作,从现在开始逐渐积累,记录一下:
使用标签选取数据:
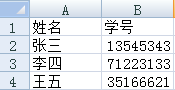
df.loc[行标签,列标签] df.loc['a':'b']#选取ab两行数据 df.loc[:,'one']#选取one列的数据
df.loc的第一个参数是行标签,第二个参数为列标签(可选参数,默认为所有列标签),两个参数既可以是列表也可以是单个字符,如果两个参数都为列表则返回的是DataFrame,否则,则为Series。
示例代码:
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
上一行代码的意思是:选取Cabin列中不为空的位置替换为“Yes”,df是一个二维数据集
这篇pandas.loc 选取指定列进行操作的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。