Python3基于sax解析xml操作示例
本文实例讲述了Python3基于sax解析xml操作。分享给大家供大家参考,具体如下:
python使用SAX解析xml
SAX是一种基于事件驱动的API。
利用SAX解析XML文档牵涉到两个部分:解析器和事件处理器。
解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;
而事件处理器则负责对事件作出相应,对传递的XML数据进行处理。
1、对大型文件进行处理;
2、只需要文件的部分内容,或者只需从文件中得到特定信息。
3、想建立自己的对象模型的时候。
在python中使用sax方式处理xml要先引入xml.sax中的parse函数,还有xml.sax.handler中的ContentHandler。
saxDemo.py
# -*- coding:utf-8 -*-
#!/usr/bin/python3
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# 元素开始调用
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print ("*****Movie*****")
title = attributes["title"]
print ("Title:", title)
# 元素结束调用
def endElement(self, tag):
if self.CurrentData == "type":
print ("Type:", self.type)
elif self.CurrentData == "format":
print ("Format:", self.format)
elif self.CurrentData == "year":
print ("Year:", self.year)
elif self.CurrentData == "rating":
print ("Rating:", self.rating)
elif self.CurrentData == "stars":
print ("Stars:", self.stars)
elif self.CurrentData == "description":
print ("Description:", self.description)
self.CurrentData = ""
# 读取字符时调用
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")
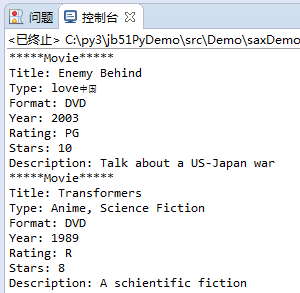
执行结果
*****Movie*****
Title: Enemy Behind
Type: love中国
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
运行结果如下图所示:
movies.xml内容:
<?xml version="1.0" encoding="utf-8"?> <collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>love中国</type> <format>DVD</format> <year>2003</year> <rating>PG</rating> <stars>10</stars> <description>Talk about a US-Japan war</description> </movie> <movie title="Transformers"> <type>Anime, Science Fiction</type> <format>DVD</format> <year>1989</year> <rating>R</rating> <stars>8</stars> <description>A schientific fiction</description> </movie> </collection>
PS:这里再为大家提供几款关于xml操作的在线工具供大家参考使用:
在线XML/JSON互相转换工具:
http://tools.jb51.net/code/xmljson
在线格式化XML/在线压缩XML:
http://tools.jb51.net/code/xmlformat
XML在线压缩/格式化工具:
http://tools.jb51.net/code/xml_format_compress
XML代码在线格式化美化工具:
http://tools.jb51.net/code/xmlcodeformat
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python操作xml数据技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。