详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰。
希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式。
比如这里给出
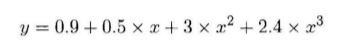
很显然,这里我们只需要假定
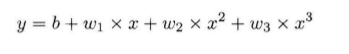
这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可。
但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢?
只将一个x作为输入合理吗?显然是不合理的,因为每一个神经元其实模拟的是wx+b的计算过程,无法模拟幂运算,所以显然我们需要将x,x的平方,x的三次方,x的四次方组合成一个向量作为输入,假设有n个不同的x值,我们就可以将n个组合向量合在一起组成输入矩阵。
这一步代码如下:
def make_features(x): x = x.unsqueeze(1) return torch.cat([x ** i for i in range(1,4)] , 1)
我们需要生成一些随机数作为网络输入:
def get_batch(batch_size=32): random = torch.randn(batch_size) x = make_features(random) '''Compute the actual results''' y = f(x) if torch.cuda.is_available(): return Variable(x).cuda(), Variable(y).cuda() else: return Variable(x), Variable(y)
其中的f(x)定义如下:
w_target = torch.FloatTensor([0.5,3,2.4]).unsqueeze(1) b_target = torch.FloatTensor([0.9]) def f(x): return x.mm(w_target)+b_target[0]
接下来定义模型:
class poly_model(nn.Module): def __init__(self): super(poly_model, self).__init__() self.poly = nn.Linear(3,1) def forward(self, x): out = self.poly(x) return out
if torch.cuda.is_available(): model = poly_model().cuda() else: model = poly_model()
接下来我们定义损失函数和优化器:
criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr = 1e-3)
网络部件定义完后,开始训练:
epoch = 0 while True: batch_x,batch_y = get_batch() output = model(batch_x) loss = criterion(output,batch_y) print_loss = loss.data[0] optimizer.zero_grad() loss.backward() optimizer.step() epoch+=1 if print_loss < 1e-3: break
到此我们的所有代码就敲完了,接下来我们开始详细了解一下其中的一些代码。
在make_features()定义中,torch.cat是将计算出的向量拼接成矩阵。unsqueeze是作一个维度上的变化。
get_batch中,torch.randn是产生指定维度的随机数,如果你的机器支持GPU加速,可以将Variable放在GPU上进行运算,类似语句含义相通。
x.mm是作矩阵乘法。
模型定义是重中之重,其实当你掌握Pytorch之后,你会发现模型定义是十分简单的,各种基本的层结构都已经为你封装好了。所有的层结构和损失函数都来自torch.nn,所有的模型构建都是从这个基类 nn.Module继承的。模型定义中,__init__与forward是有模板的,大家可以自己体会。
nn.Linear是做一个线性的运算,参数的含义代表了输入层与输出层的结构,即3*1;在训练阶段,有几行是Pytorch不同于别的框架的,首先loss是一个Variable,通过loss.data可以取出一个Tensor,再通过data[0]可以得到一个int或者float类型的值,我们才可以进行基本运算或者显示。每次计算梯度之前,都需要将梯度归零,否则梯度会叠加。个人觉得别的语句还是比较好懂的,如果有疑问可以在下方评论。
下面是我们的拟合结果
其实效果肯定会很好,因为只是一个非常简单的全连接网络,希望大家通过这个小例子可以学到Pytorch的一些基本操作。往后我们会继续更新,完整代码请戳,https://github.com/ZhichaoDuan/PytorchCourse
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。