pytorch + visdom 处理简单分类问题的示例
环境
系统 : win 10
显卡:gtx965m
cpu :i7-6700HQ
python 3.61
pytorch 0.3
包引用
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
数据准备
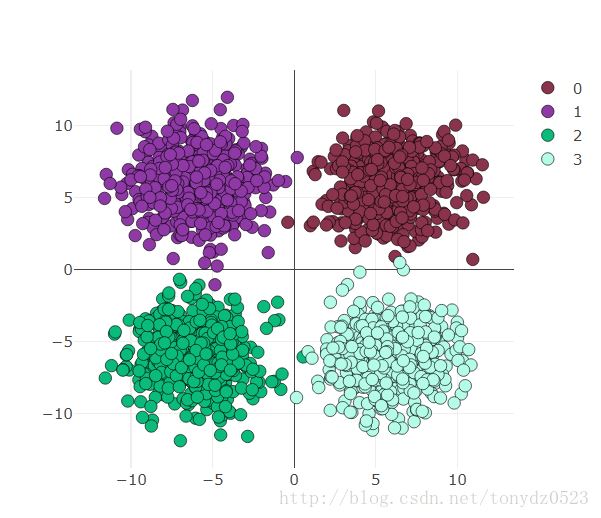
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()
可视化如下看一下:
visdom可视化准备
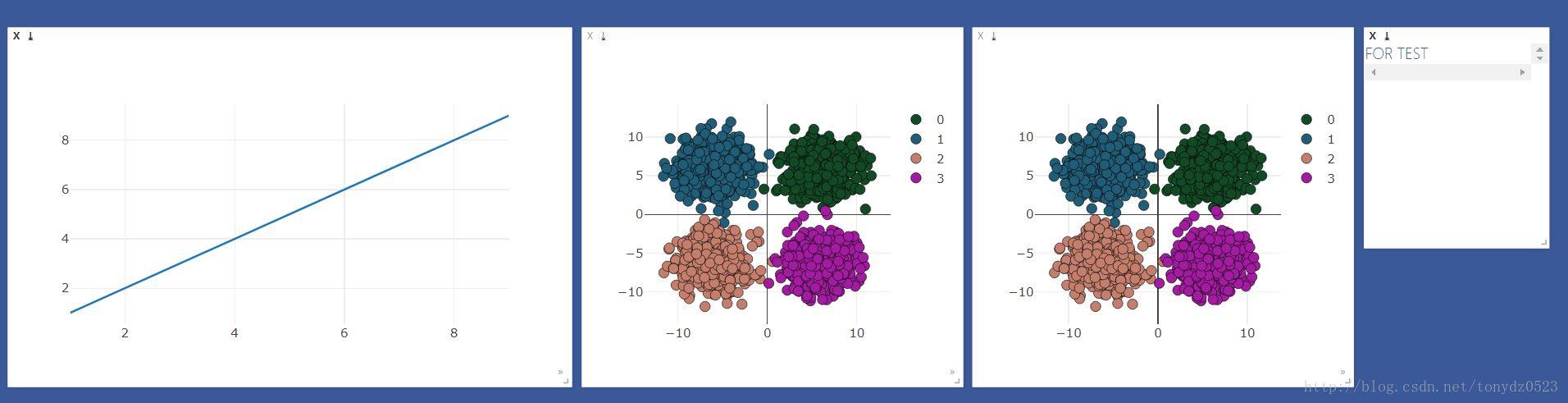
先建立需要观察的windows
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)
效果如下:
逻辑回归处理
输入2,输出4
logstic = nn.Sequential( nn.Linear(2,4) )
gpu还是cpu选择:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")
优化器和loss函数:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
训练2000次:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()
训练过成观察及可视化:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
.format(accuracy,loss.data[0],time.time()-start_time),win =text)
我们先用cpu运行一次,结果如下:
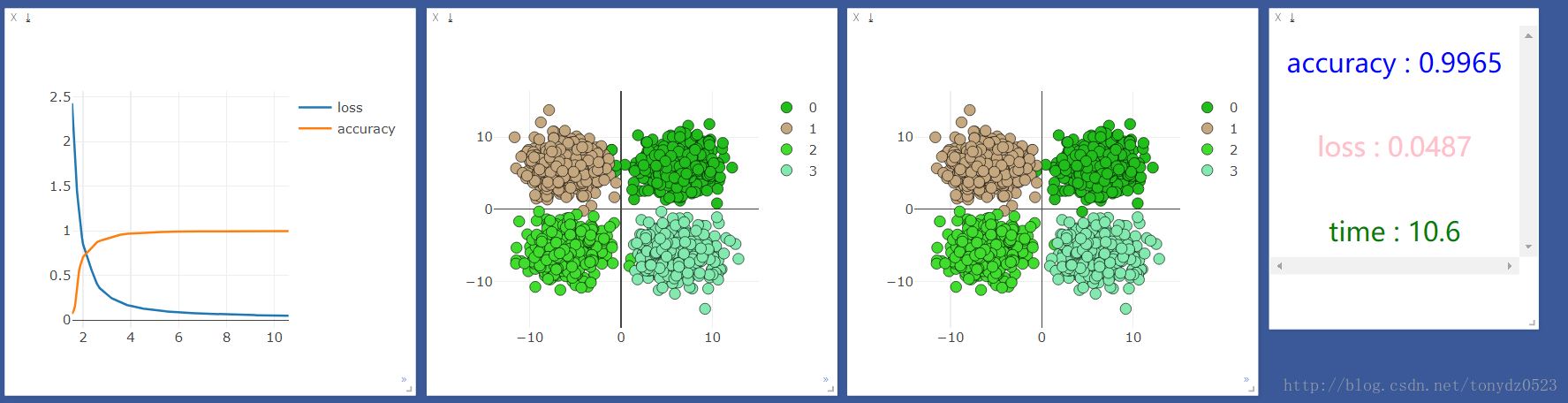
然后用gpu运行一下,结果如下:
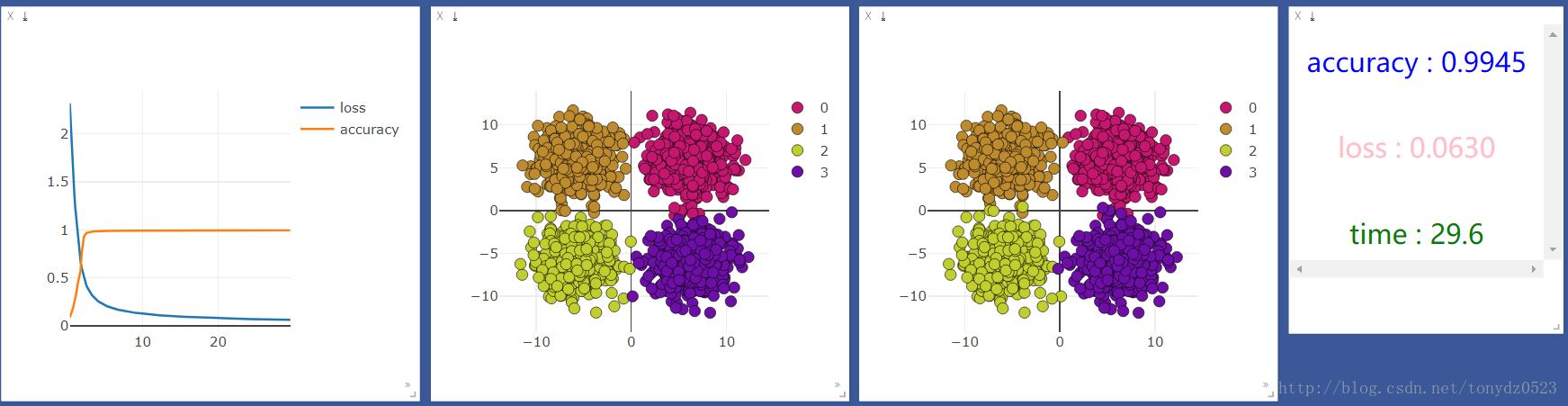
发现cpu的速度比gpu快很多,但是我听说机器学习应该是gpu更快啊,百度了一下,知乎上的答案是:

我的理解就是gpu在处理图片识别大量矩阵运算等方面运算能力远高于cpu,在处理一些输入和输出都很少的,还是cpu更具优势。
添加神经层:
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )
添加一层10单元神经层,看看效果是否会有所提升:
使用cpu:
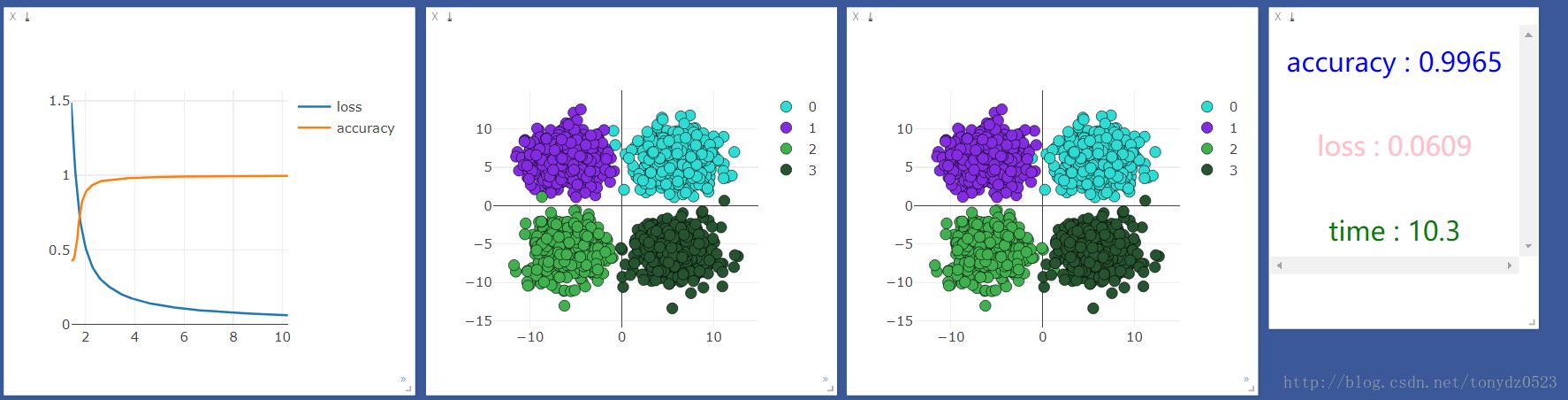
使用gpu:
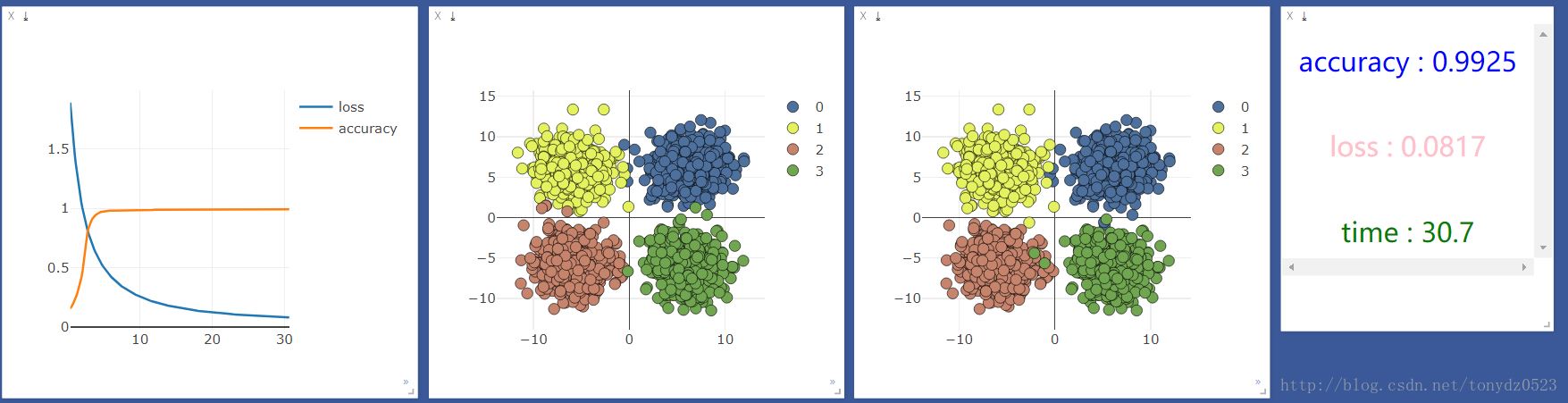
比较观察,似乎并没有什么区别,看来处理简单分类问题(输入,输出少)的问题,神经层和gpu不会对机器学习加持。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。