pandas DataFrame实现几列数据合并成为新的一列方法
问题描述
我有一个用于模型训练的DataFrame如下图所示:
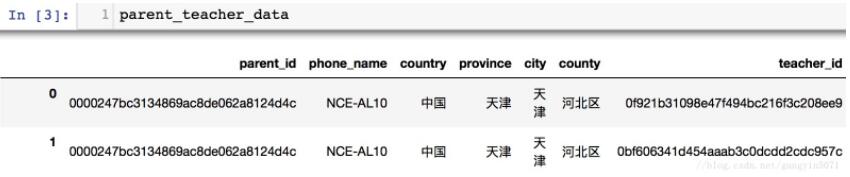
其中的country、province、city、county四列其实是位置信息的不同层级,应该合成一列用于模型训练
方法:
parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county']
就可以把四列合并成新的列address
如果某一列是非str类型的数据,那么我们需要用到map(str)将那一列数据类型做转换:
dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone"] + dataframe["address”]
以上这篇pandas DataFrame实现几列数据合并成为新的一列方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。