Python中存取文件的4种不同操作
前言:
最近开始学习tensorflow框架,选修课让任选一种框架实现mnist手写数字的识别分类。小詹也就随着大流选择了 tf 框架,跟着教程边学边做,小詹用了不同的神经网络实现了识别分类,其中有一个步骤是将训练过程得到的模型进行保存,在之后的测试中加载并使用该模型。想到这种先保存再加载调用的过程,之前很多地方都遇到过呀,最简单常用的就是python中文件的存取哇!于是乎,小詹夜观星象,就着手整理记录各种文件存取的骚操作,具体如下。
(PS:虽然我知道技术文章太长,耐心看完的人很少,曝光率和点赞率会下降,更不会有什么收益,但是还是想记录下自己学习过程中的一些笔记,以后自己或者别人查起来方便些!)
方法预览
●Python内置方法
●numpy模块方法
●os模块方法
●csv模块方法
Python内置方法
在不需要借助任何外界库的前提下,python内置方法其实也可以完成我们需要的文件存取任务,这里主要介绍几种python内置方法的使用方式,最后再给出一个实际案例展示:
1、open()方法
file object = open(file_name [, access_mode][, buffering])
该方法意义在于按照指定模式打开文件,其中,各个参数的含义如下:
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
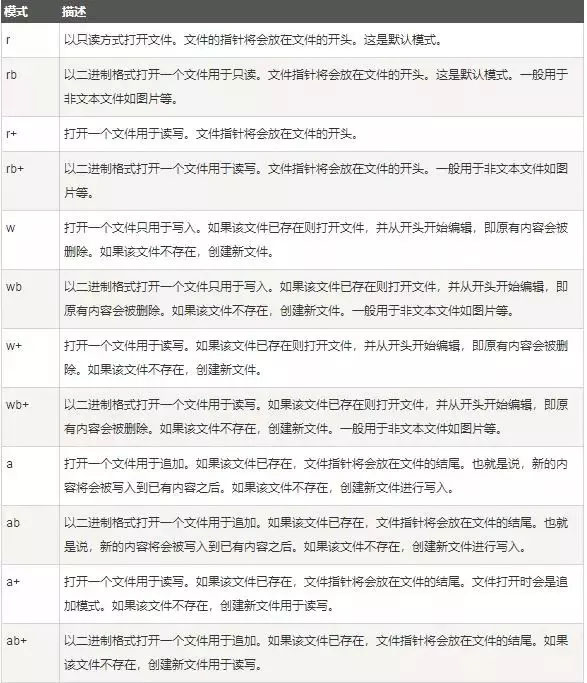
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。常用文件访问模式见下图(来源于网络)
buffering: 如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
2、close()方法
fileObject.close()
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
3、write ()方法
fileObject.write(string)
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。write()方法不会在字符串的结尾添加换行符('\n');被传递的参数是要写入到已打开文件的内容。
4、read () 方法
fileObject.read([count])read()
方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
5、举例分析
一般情况,建议小伙伴们使用with ...as...写法,这种会在执行完代码块后自动close,既可以简化程序,又可以避免自己粗心或者其他原因造成的不必要错误,下面给出一个实际案例。
#先用open方法打开(不存在则创建)一个文件,
#write方法写入内容,这里with写法不用手动close
#注意这里是模式‘a',意味着写入内容不覆盖已有内容
with open('test.txt','a') as file_test:
file_test.write('小詹是个美男子!\n')
file_test.write('请关注公众号【小詹学python】!\n')
#注意利用read方法读取内容,模式要设置为可读模式
#read()方法不带参数,表示默认读取最长内容
with open('test.txt','r') as file_test:
str = file_test.read()
print(str)
输出结果会在目录下多出一个test.txt文件,并读取后输出所有内容,下图为执行了三次的结果,说明模式‘a'不会覆盖已有内容(重要的事情说三遍!)

numpy模块方法
这里主要介绍numpy模块中的两个常用方法,用于保存读取数据。
np.loadtxt(filename, dtype=int, delimiter=' ') np.savetxt(filename, a, fmt="%d", delimiter=",")
其中,filename为要保存或读取的文件名,a为存取的内容,delimiter为分隔符号。这个使用很简单,代码如下:
import numpy as np
a=np.arange(0,10,0.5).reshape(4,-1)
#改为保存为整数,以逗号分隔
np.savetxt("a.txt",a,fmt="%d",delimiter=",")
#load时也要指定为逗号分隔
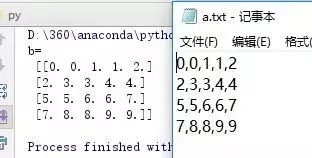
b = np.loadtxt("a.txt",delimiter=",")
print('b=\n',b)
其运行结果,创建了一个名为'a.txt‘ 的文件,保存了数组,并print打印出来读取结果,如下图:
os模块方法
python中的os模块很强大,提供了许多文件处理操作的方法。以下列举出常用的几种方法。
1、os.open()
os.open(file, flags[, mode]);
其中,参数含义为:
file -- 要打开的文件
flags -- 该参数可以是以下选项,多个使用 "|" 隔开:
- os.O_RDONLY: 以只读的方式打开
- os.O_WRONLY: 以只写的方式打开
- os.O_RDWR : 以读写的方式打开
- os.O_NONBLOCK: 打开时不阻塞
- os.O_APPEND: 以追加的方式打开
- os.O_CREAT: 创建并打开一个新文件
- os.O_TRUNC: 打开一个文件并截断它的长度为零(必须有写权限)
- os.O_EXCL: 如果指定的文件存在,返回错误
- os.O_SHLOCK: 自动获取共享锁
- os.O_EXLOCK: 自动获取独立锁
- os.O_DIRECT: 消除或减少缓存效果
- os.O_FSYNC : 同步写入
- os.O_NOFOLLOW: 不追踪软链接
2、os.rename(current_name,new_name)方法用于更改文件名称
3、os.remove(filename)方法用于删除指定文件
4、os.mkdir('newdir')方法用于创建单层目录,如果该目录已存在会抛出异常
5、os.chdir('newdir')方法用于改变当前工作目录
6、os.getcwd()方法获取当前工作目录
7、os.write(fd,str)向指定文件写入内容,注意str要转换成byte
这里注意针对内容的写入举例,注意str要转换成byte,否则会报错(a bytes-like object is required, not ‘str')!
import os
# # 打开文件
fd = os.open("f1.txt",os.O_RDWR|os.O_CREAT)
# # 写入字符串
line = "this is xiaozhan"
b = str.encode(line)
os.write(fd,b)
# #直接写str报错:a bytes-like object is required, not ‘str'
os.close(fd)
#以可读模式打开
fd = os.open("f1.txt",os.O_RDWR)
ret = os.read(fd,16)
print(ret)
os.close(fd)
print('finish close')
# os.remove('f1.txt')
运行结果如下:
csv模块方法
和前几种方法一样,主要是读取和写入两个部分。主要依靠csv.reader(),csv.writer()和writerow()方法。和前边几种大同小异,这里直接代码中讲解基础的使用方式。
import csv
with open('l.csv', 'w',newline='') as csvfile:
#csv.writer()方法创建
eWriter = csv.writer(csvfile)
#用writerow()方法逐行写入
eWriter.writerow(['ID', '名字', '粉丝数量'])
eWriter.writerow(['xiaoxiaozhantongxue','小詹学python',15000])
eWriter.writerow(['xiaoxiaozhantongxue','小詹学python',15000])
eWriter.writerow(['xiaoxiaozhantongxue','小詹学python',15000])
#打开文件,用with打开可以不用去特意关闭file了,python3不支持file()打开文件,只能用open()
with open('l.csv','r') as csvfile:
#读取csv文件,返回的是迭代类型
read = csv.reader(csvfile)
for i in read:
print(i)
运行结果如下图:

以上就是本次整理的内容了,方便自己查阅也希望对各位读者有一丢丢用噢!文章太长,耐心看到这的,我得给你点个赞,送你一个么么哒。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。