如何优雅地改进Django中的模板碎片缓存详解
前言
本文主页给大家介绍了关于如何改进Django中模板碎片缓存的相关内容,关于Django模板碎片缓存大家可以先看看这篇文章,下面话不多说了,来一起看看详细的介绍吧
起步
Django 的缓存体系提供了模板片段缓存:
{% load cache %}
{% cache 500 sidebar %}
.. sidebar ..
{% endcache %}
但使用这个模板缓存还是需要每次都把需要的变量 sidebar 传给模板,不然当缓存过期时碎片是空白的。于是就需要的视图中获取这些数据:
def test_view(request):
# code...
sidebar = get_data()
return render(reqeust, 'test_view.html', {'sidebar': sidebar})
如果这个数据获取的过程比较耗时,那么这个碎片缓存形同虚设。
低级缓存
使用低级缓存能解决数据获取耗时问题:
from django.core.cache import cache
def get_data():
key = 'hot-course'
result = cache.get(key)
if result:
return result
# 比较耗时的数据获取
result = Course.objects.filter().order_by('-fav_num')[:10]
cache.set(key, result, 600) # 保存至缓存
return result
这样一般就能解决数据来源耗时问题,一般用了这个方式就不会再用模板碎片缓存了,不然内存中就有两个缓存了,一个是原始数据,另一个是渲染成 html 代码的结果。有点多余,内存宝贵应该用于刀刃上,而且两个缓存的方式极不优雅。
使用这种底层 api 后,还是需要把数据传递到视图层,如果是公共部分的如轮播部分的视图,是会被其他模板 include 的,那就需要其他视图函数也都获取一次数据,再传递到模板层。重复的代码会很多。
有没有一种好的办法解决这种情况呢?
优雅的改进碎片缓存
改进的碎片缓存需要能按需获取,最好不需要视图层的参与。这个要求可以通过标签来实现,我们来自己实现一下这个缓存标签,在此之前呢,需要做个通用的缓存工具,能够传入数据获取的函数来做回调,这部分其实和 Django 的 django.templatetags.CacheNode 类基本一样。我这边就写与其不一样的地方:
class UserCacheNode(Node): """ 优雅的自定义模板碎片缓存 """ def __init__(self, nodelist, expire_time_var, fragment_name, vary_on, cache_name, fun=None): # ... self.fun = fun # 用于数据获取的回调函数 def render(self, context:dict): # ... if value is None: if self.fun: # 实行回调 context.update(self.fun(*vary_on)) value = self.nodelist.render(context) fragment_cache.set(cache_key, value, expire_time) # 保存至缓存 return value
然后是制作自定义标签:
def get_hot_course():
# 做会调用,函数返回字典
print("call hot course")
hot_courses = Course.objects.filter().order_by('stu_nums')[:5]
return locals()
@register.tag('hot_course_cache') # 自定义的标签名称
def hot_course_cache(parser, token):
nodelist = parser.parse(('endcache',))
parser.delete_first_token()
tokens = token.split_contents()
cache_name = None
return UserCacheNode(
nodelist, parser.compile_filter(tokens[1]),
tokens[2], # fragment_name can't be a variable.
[parser.compile_filter(t) for t in tokens[3:]],
cache_name,
fun=get_hot_course, # 回调函数
)
然后在模板中就可以这么使用:
{% load course_tag %}
{% hot_course_cache 500 hot_courses %}
...hot_courses...
{% endcache %}
通过用自定义标签的方式,就无需视图层的参与了,缓存标签的使用方式也和体系中的 cache 相似,由于是自定义的标签,一些 IDE 会有一些警告,比如我的开发环境:
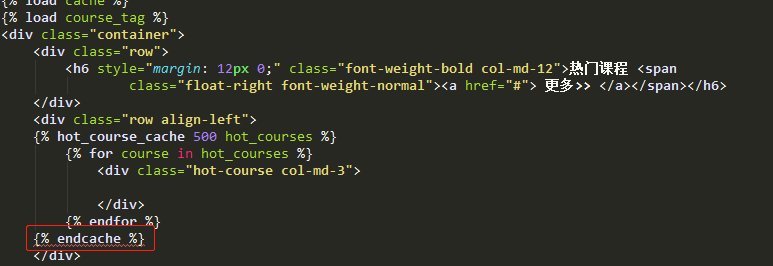
运行上是没问题的,IDE 可能对这类自定义标签的支持度不是很好吧。
参考
Custom template tags and filters
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。