Django 多语言教程的实现(i18n)
最近公司准备扩张海外业务,所以要给 Django 系统添加 国际化与本土化 支持。国际化一般简称 i18n ,代表 Internationalization 中 i 和 n 有 18 个字母;本地化简称 L10n ,表示 Localization 中 l 和 n 中有 10 个字母。有趣的一点是,一般会用小写的 i 和大写的 L 防止混淆。
简单来说:i18n 是为国际化搭建框架,L10n 是针对不同地区的适配。举个简单的例子:
i18n:
datetime.now().strftime('%Y/%m/%d') # before i18n
datetime.now().strftime(timeformat) # after i18n
L10n:
timeformat = {
'cn': '%Y/%m/%d',
'us': '%m/%d/%Y',
'fr': '%d/%m/%Y',
...
}
更加具体的定义可以看https://www.w3.org/International/questions/qa-i18n的解释。
i18n 的范围非常广,包括多语言、时区、货币单位、单复数、字符编码甚至是文字阅读顺序(RTL)等等。这篇文章只关注 i18n 的多语言 方面。
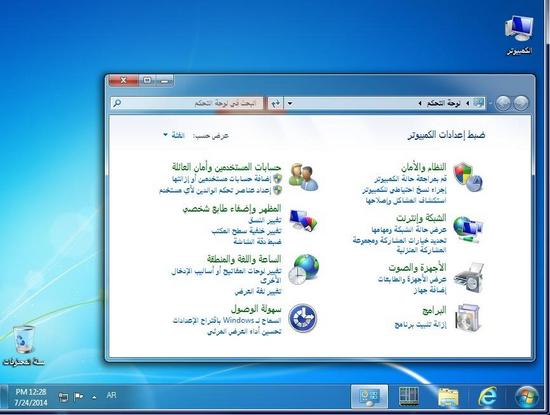
↑ 阿拉伯语的 windows 系统,文字甚至界面的方向都与中文版的相反
基本步骤
Django 作为一个大而全的框架,已经提供了一套多语言的解决方案,我稍微对比了一下,并没能找到在 Django 体系下比官方方案还好用的库。Django 的方案可以简单分为四步:
- 一些必要的配置
- 在代码中标记需要翻译的文本
- 使用 makemessages 命令生成 po 文件
- 编译 compilemessages 命令编译 mo 文件
下面我们详细来看看
第一步:配置
首先在 settings.py 中加入这几个内容
LOCALE_PATHS = (
os.path.join(__file__, 'language'),
)
MIDDLEWARE = (
...
'django.middleware.locale.LocaleMiddleware',
...
)
LANGUAGES = (
('en', 'English'),
('zh', '中文'),
)
LOCALE_PATHS :指定下面第三步和第四步生成文件的位置。老版的 Django 需要手动新建好这个目录。
LocaleMiddleware :可以让 Django 识别并选择合适的语言。
LANGUAGES :指定了这个工程能提供哪些语言。
第二步:标记文本
之前没有多语言的需要,所以大家在 AJAX 相应代码中直接写了中文,比如这样:
return JsonResponse({"msg": "内容过长", "code": 1, "data": None})
现在需要多语言了,就需要告诉 Django 哪些内容是需要翻译的。对于上面的例子来说,就是写成这样:
from django.utils.translation import gettext as _
return JsonResponse({"msg": _("内容过长"), "code": 1, "data": None})
这里使用 gettext 函数将原本的字符串包裹起来,这样的话,Django 就可以根据当前语言返回合适的字符串。一般会使用单个下划线 _ 提高可读性。
因为我司几乎所有前后端通信都使用 AJAX,所以并没有怎么用上 Django 的模板功能(顺便一提,我司前端使用的多语言工具是 i18next )。不过在这里也一并写下 Django 模板的标记方法:
<title>{% trans "This is the title." %}</title>
<title>{% trans myvar %}</title>
其中 trans 标签告诉 Django 需要翻译这个括号里面的内容。更具体的用法可以参考官方文档。
第三步: makemessages
在执行这一步之前,请先通过 xgettext --version 确认自己是否安装了GNU gettext。GNU gettext 是一个标准 i18n L10n 库,Django 和很多其他语言和库的多语言模块都调用了 GNU gettext,所以接下来讲的一些 Django 特性实际上要归功于 GNU gettext。如果没有安装的话可以通过下面的方法安装:
ubuntu:
$ apt update $ apt install gettext
$ brew install gettext $ brew link --force gettext
安装完 GNU gettext 后,对 Django 工程执行下面的命令
$ python3 manage.py makemessages --local en
之后可以找到生成的文件: language/en/LC_MESSAGES/django.po 。把上面命令中的 en 替换成其他语言,就可以生成不同语言的 django.po 文件。里面的内容大概是这样的:
#: path/file.py:397 msgid "订单已删除" msgstr "" ...
Django 会找到被 gettext 函数包裹的所有字符串,以 msgid 的形式保存在 django.po 。每个 msgid 下面的 msgstr 就代表你要把这个 msgid 翻译成什么。通过修改这个文件可以告诉 Django 翻译的内容。同时通过注释说明了这个 msgid 出现在哪个文件的哪一行。
关于这个文件,发现几点有趣的特性:
- Django 会把多个文件中相同的 msgid 归类在一起。「一次编辑,到处翻译」
- 如果以后源码中某个 msgid 被删了,那么再次执行 makemessages 命令后,这个 msgid 和它的 msgstr 会以注释的形式继续保存在 django.po 中。
- 既然源码中的字符串只是一个所谓的 id,那么我就可以在源码中写没有实际含义的字符串,比如 _("ERROR_MSG42"),然后将 "ERROR_MSG42" 同时翻译成中文和英文。
- 这个文件中会保留模板字符串的占位符,比如可以使用命名占位符做到在不同语言中使用不同占位符顺序的功能,下面给出了一个例子:
py file:
_('Today is {month} {day}.').format(month=m, day=d)
_('Today is %(month)s %(day)s.') % {'month': m, 'day': d}
po file
msgid "Today is {month} {day}."
msgstr "Aujourd'hui est {day} {month}."
msgid "Today is %(month)s %(day)s."
msgstr "Aujourd'hui est %(day)s %(month)s."
第四步: compilemessages
修改好 django.po 文件后,执行下面的命令:
$ python3 manage.py compilemessages --local en
Django 会调用程序,根据 django.po 编译出一个名为 django.mo 的二进制文件,位置和 django.po 所在位置相同。这个文件才是程序执行的时候会去读取的文件。
执行完上面四步后,修改浏览器的语言设置,就可以看到 Django 的不同输出了。
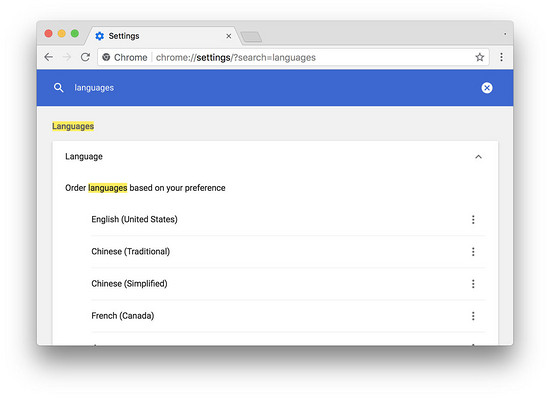
↑ Chrome 的语言设置
高级特性
i18n_patterns
有的时候,我们希望可以通过 URL 来选择不同的语言。这样做有很多好处,比如同一个 URL 返回的数据的语言一定是一致的。Django 的文档就使用了这种做法:
简体中文:https://docs.djangoproject.com/zh-hans/2.0/
英文:https://docs.djangoproject.com/en/2.0/
具体的做法是在 URL 中添加 <slug:slug>
urlpatterns = ([
path('category/<slug:slug>/', news_views.category),
path('<slug:slug>/', news_views.details),
])
详细的做法可以参考 Django 的官方文档。
Django 如何决定使用哪种语言
我们之前讲过 LocaleMiddleware 可以决定使用何种语言。具体来说, LocaleMiddleware 是按照下面的顺序(优先级递减):
i18n_patterns-
request.session[settings.LANGUAGE_SESSION_KEY] request.COOKIES[settings.LANGUAGE_COOKIE_NAME]request.META['HTTP_ACCEPT_LANGUAGE'],即 HTTP 请求中的Accept-Languageheadersettings.LANGUAGE_CODE
我司选择把语言信息放到 Cookies 中,当用户手动选择语言时,可以让前端直接修改 Cookies,而不需要请求后台的某个接口。没有手动设置过语言的用户就没有这个 Cookies,跟随浏览器设置。话说 settings.LANGUAGE_COOKIE_NAME 的默认值是 django_language ,前端不想在他们的代码中出现 django ,所以我在 settings.py 中添加了 LANGUAGE_COOKIE_NAME = app_language :joy:。
你也可以通过 request.LANGUAGE_CODE 在 View 中手动获知 LocaleMiddleware 选用了哪种语言。你甚至可以通过 activate 函数手动指定当前线程使用的语言:
from django.utils.translation import activate
activate('en')
ugettext
Python2 时代,为了区分 unicode strings 和 bytestrings,有 ugettext 和 gettext 两个函数。在 Python3 中,由于字符串编码的统一, ugettext 和 gettext 是等价的。官方说未来可能会废弃 ugettext ,但是截止到现在(Django 2.0), ugettext 还没废弃。
gettext_lazy
这里先用一个例子直观地看一下 gettext_lazy 和 gettext 的区别
from django.utils.translation import gettext, gettext_lazy, activate, get_language
gettext_str = gettext("Hello World!")
gettext_lazy_str = gettext_lazy("Hello World!")
print(type(gettext_str))
# <class 'str'>
print(type(gettext_lazy_str))
# <class 'django.utils.functional.lazy.<locals>.__proxy__'>
print("current language:", get_language())
# current language: zh
print(gettext_str, gettext_lazy_str)
# 你好世界! 你好世界!
activate("en")
print("current language:", get_language())
# current language: en
print(gettext_str, gettext_lazy_str)
# 你好世界! Hello World!
gettext 函数返回的是一个字符串,但是 gettext_lazy 返回的是一个代理对象。这个对象会在被使用的时候,才根据当前线程中语言决定翻译成什么文字。
这个功能在 Django 的 models 中尤其的有用。因为 models 中定义字符串的代码只会执行一次。在之后的请求中,根据语言的不同,这个所谓字符串要有不同的表现。
from django.utils.translation import gettext_lazy as _
class MyThing(models.Model):
name = models.CharField(help_text=_('This is the help text'))
class YourThing(models.Model):
kind = models.ForeignKey(
ThingKind,
on_delete=models.CASCADE,
related_name='kinds',
verbose_name=_('kind'),
)
使用 AST / FST 修改源码
由于我司工程非常庞大,人力给每个字符串添加 _( ... ) 过于繁琐。所以我试图寻找一种自动化的方式。
一开始选择的是 Python 内置的 ast (Abstract syntax tree 语法抽象树) 模块 。基本思路是通过 ast 找到工程中的所有字符串,再给这些字符串添加 _( ... ) 。最后把修改后的语法树重新转为代码。
但是由于 ast 对格式信息的支持不佳,修改代码后容易造成格式混乱。所以找到了名为 FST (Full Syntax Tree 全面抽象树) 的改进方式。我选择的 FST 库是 redbaron 。核心的代码如下:
root = RedBaron(original_code)
for node in root.find_all("StringNode"):
if (
has_chinese_char(node)
and not is_aleady_gettext(node)
and not is_docstring(node)
):
node.replace("_({})".format(node))
modified_code = root.dumps()
我把完整的代码放到了 Gist 上,因为是一个一次性脚本,写的比较随意,大家可以参考。
使用 redbaron 的过程中也发现了一些问题,一并记录这里:最大问题是 redbaron 已经停止维护 了!所以不能支持一些新语法,比如 Python3.6 的 f-string。其次是这个库和 ast 标准库相比,运行速度很慢,每次跑这个脚本我的电脑都发出了飞机引擎般的声音。第三点是会产生一些奇怪的格式:
修改前:
OutStockSheet = {
1: '未出库',
2: '已出库',
3: '已删除'
}
修改后( '已删除' 右边的括号跑到了下一行):
OutStockSheet = {
1: _('未出库'),
2: _('已出库'),
3: _('已删除'
)}
最后一点倒是可以通过格式化工具解决,问题不大。
utf8 vs utf-8
项目中有些 py 文件比较老,在文件开头使用了 # coding: utf8 的标示。对于 Python 来说,utf8 是 utf-8 的别名,所以没有任何问题。Django 在调用 GNU gettext 时,会使用参数指定编码为 utf-8,但是 GNU 也会读取文件中的编码标示,而且它的优先级更高。不幸的是 utf8 对 GNU gettext 来说是一个未知编码,于是 GNU gettext 会降级使用 ASCII 编码,然后在遇到中文字符时报错(真笨!):
$ python3 manage.py makemessages --local en ... xgettext: ./path/filename.py:1: Unknown encoding "utf8". Proceeding with ASCII instead. xgettext: Non-ASCII comment at or before ./path/filename.py:26.
所以我需要把 # coding: utf8 改成 # coding: utf-8 ,或者干脆删掉这行,反正 Python3 已经默认使用 utf-8 编码了。
总结
Django (和其背后的 GNU gettext) 的多语言功能非常全面,堪称博大精深,比如处理单复数的ngettext,处理多义词的pgettext。HTTP 响应中使用翻译后的文本,但是在日志中留下翻译前文本的gettext_noop。
这篇文章主要讲了我在实践中用到的功能和遇到的坑,希望可以帮助大家了解 Django 多语言的基本用法。欢迎大家评论:clap:。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。