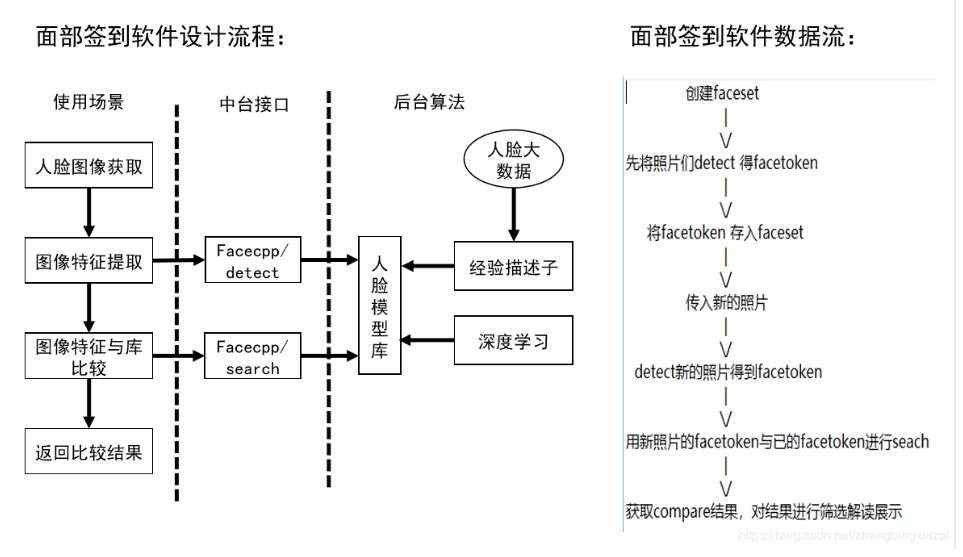
使用 Python 实现文件递归遍历的三种方式
今天有个脚本需要遍历获取某指定文件夹下面的所有文件,我记得很早前也实现过文件遍历和目录遍历的功能,于是找来看一看,嘿,不看不知道,看了吓一跳,原来之前我竟然用了这么搓的实现。
先发出来看看:
def getallfiles(dir):
"""遍历获取指定文件夹下面所有文件"""
if os.path.isdir(dir):
filelist = os.listdir(dir)
for ret in filelist:
filename = dir + "\\" + ret
if os.path.isfile(filename):
print filename
def getalldirfiles(dir, basedir):
"""遍历获取所有子文件夹下面所有文件"""
if os.path.isdir(dir):
getallfiles(dir)
dirlist = os.listdir(dir)
for dirret in dirlist:
fullname = dir + "\\" + dirret
if os.path.isdir(fullname):
getalldirfiles(fullname, basedir)
我是用了 2 个函数,并且每个函数都用了一次 listdir,只是一次用来过滤文件,一次用来过滤文件夹,如果只是从功能实现上看,一点问题没有,但是这…太不优雅了吧。
开始着手优化,方案一:
def getallfiles(dir):
"""使用listdir循环遍历"""
if not os.path.isdir(dir):
print dir
return
dirlist = os.listdir(dir)
for dirret in dirlist:
fullname = dir + "\\" + dirret
if os.path.isdir(fullname):
getallfiles(fullname)
else:
print fullname
从上图可以看到,我把两个函数合并成了一个,只调用了一次 listdir,把文件和文件夹用 if~else~ 进行了分支处理,当然,自我调用的循环还是存在。
有木有更好的方式呢?网上一搜一大把,原来有一个现成的 os.walk() 函数可以用来处理文件(夹)的遍历,这样优化下就更简单了。
方案二:
def getallfilesofwalk(dir):
"""使用listdir循环遍历"""
if not os.path.isdir(dir):
print dir
return
dirlist = os.walk(dir)
for root, dirs, files in dirlist:
for file in files:
print os.path.join(root, file)
只是从代码实现上看,方案二是最优雅简洁的了,但是再翻看 os.walk() 实现的源码就会发现,其实它内部还是调用的 listdir 完成具体的功能实现,只是它对输出结果做了下额外的处理而已。
附上os.walk()的源码:
from os.path import join, isdir, islink
# We may not have read permission for top, in which case we can't
# get a list of the files the directory contains. os.path.walk
# always suppressed the exception then, rather than blow up for a
# minor reason when (say) a thousand readable directories are still
# left to visit. That logic is copied here.
try:
# Note that listdir and error are globals in this module due
# to earlier import-*.
names = listdir(top)
except error, err:
if onerror is not None:
onerror(err)
return
dirs, nondirs = [], []
for name in names:
if isdir(join(top, name)):
dirs.append(name)
else:
nondirs.append(name)
if topdown:
yield top, dirs, nondirs
for name in dirs:
path = join(top, name)
if followlinks or not islink(path):
for x in walk(path, topdown, onerror, followlinks):
yield x
if not topdown:
yield top, dirs, nondirs
至于 listdir 和 walk 在输出时的不同点,主要就是 listdir 默认是按照文件和文件夹存放的字母顺序进行输出,而 walk 则是先输出顶级文件夹,然后是顶级文件,再输出第二级文件夹,以及第二级文件,以此类推,具体大家可以把上面脚本拷贝后自行验证。
总结
以上所述是小编给大家介绍的使用 Python 实现文件递归遍历的三种方式,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!