Django 中使用流响应处理视频的方法
起步
利用 html5 的 <video> 标签可以播放:
<video width="320" height="240" controls> <source src="/static/video/demo.mp4" type="video/mp4"> 您的浏览器不支持Video标签。 </video>
但是这样的方式,视频中的进度条无法使用,而且以静态文件方式返回的话,后台的程序会占用大量的内存。
使用响应流的方式能很好的解决这两个问题。
StreamingHttpResponse
大多数 Django 响应使用 HttpResponse 。这意味着响应的主体内置在内存中,并以单件形式发送到 HTTP 客户端。而如果用 StreamingHttpResponse 的方式则可以以 chunks (部分块)的方式返回。一个很简单的例子就是:
from django.http import StreamingHttpResponse def hello(): yield 'Hello,' yield 'there!' def test(request): return StreamingHttpResponse(hello)
根据 WSGI 协议中的,当服务器调用时,应用程序对象必须返回一个可迭代的,产生零个或多个字节串。因此我们可以通过给服务器提供生成器来完成流响应的功能。
常见的使用 StreamingHttpResponse 是一些大文件的下载等,利用它还能完成断点续传的功能。
视频流
使用视频流时可以从请求头部中获得起始字节数。
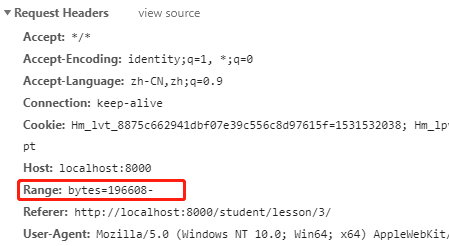
这字段似乎是浏览器自动提供的,因为html代码中,我只需要改下视频的 src 的从静态地址变成路由方式而已。对于响应体而言,也要提供响应体返回的块的一个范围:

Content-Range 分别表示了 起始字节号-终止字节号/文件总字节 ,该响应体的内容包含了文件该范围内的内容。处理视频流的代码如下:
import re
import os
from wsgiref.util import FileWrapper
from django.http import StreamingHttpResponse
def file_iterator(file_name, chunk_size=8192, offset=0, length=None):
with open(file_name, "rb") as f:
f.seek(offset, os.SEEK_SET)
remaining = length
while True:
bytes_length = chunk_size if remaining is None else min(remaining, chunk_size)
data = f.read(bytes_length)
if not data:
break
if remaining:
remaining -= len(data)
yield data
def stream_video(request, path):
"""将视频文件以流媒体的方式响应"""
range_header = request.META.get('HTTP_RANGE', '').strip()
range_re = re.compile(r'bytes\s*=\s*(\d+)\s*-\s*(\d*)', re.I)
range_match = range_re.match(range_header)
size = os.path.getsize(path)
content_type, encoding = mimetypes.guess_type(path)
content_type = content_type or 'application/octet-stream'
if range_match:
first_byte, last_byte = range_match.groups()
first_byte = int(first_byte) if first_byte else 0
last_byte = first_byte + 1024 * 1024 * 8 # 8M 每片,响应体最大体积
if last_byte >= size:
last_byte = size - 1
length = last_byte - first_byte + 1
resp = StreamingHttpResponse(file_iterator(path, offset=first_byte, length=length), status=206, content_type=content_type)
resp['Content-Length'] = str(length)
resp['Content-Range'] = 'bytes %s-%s/%s' % (first_byte, last_byte, size)
else:
# 不是以视频流方式的获取时,以生成器方式返回整个文件,节省内存
resp = StreamingHttpResponse(FileWrapper(open(path, 'rb')), content_type=content_type)
resp['Content-Length'] = str(size)
resp['Accept-Ranges'] = 'bytes'
return resp
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。