python实现机器学习之多元线性回归
总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便。
一元线性回归实现代码
下面是多元线性回归用Python实现的代码:
import numpy as np def linearRegression(data_X,data_Y,learningRate,loopNum): W = np.zeros(shape=[1, data_X.shape[1]]) # W的shape取决于特征个数,而x的行是样本个数,x的列是特征值个数 # 所需要的W的形式为 行=特征个数,列=1 这样的矩阵。但也可以用1行,再进行转置:W.T # X.shape[0]取X的行数,X.shape[1]取X的列数 b = 0 #梯度下降 for i in range(loopNum): W_derivative = np.zeros(shape=[1, data_X.shape[1]]) b_derivative, cost = 0, 0 WXPlusb = np.dot(data_X, W.T) + b # W.T:W的转置 W_derivative += np.dot((WXPlusb - data_Y).T, data_X) # np.dot:矩阵乘法 b_derivative += np.dot(np.ones(shape=[1, data_X.shape[0]]), WXPlusb - data_Y) cost += (WXPlusb - data_Y)*(WXPlusb - data_Y) W_derivative = W_derivative / data_X.shape[0] # data_X.shape[0]:data_X矩阵的行数,即样本个数 b_derivative = b_derivative / data_X.shape[0] W = W - learningRate*W_derivative b = b - learningRate*b_derivative cost = cost/(2*data_X.shape[0]) if i % 100 == 0: print(cost) print(W) print(b) if __name__== "__main__": X = np.random.normal(0, 10, 100) noise = np.random.normal(0, 0.05, 20) W = np.array([[3, 5, 8, 2, 1]]) #设5个特征值 X = X.reshape(20, 5) #reshape成20行5列 noise = noise.reshape(20, 1) Y = np.dot(X, W.T)+6 + noise linearRegression(X, Y, 0.003, 5000)
特别需要注意的是要弄清:矩阵的形状
在梯度下降的时候,计算两个偏导值,这里面的矩阵形状变化需要注意。
梯度下降数学式子:
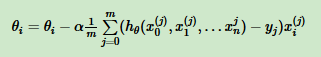
以代码中为例,来分析一下梯度下降中的矩阵形状。
代码中设了5个特征。
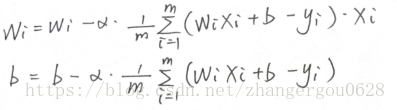
WXPlusb = np.dot(data_X, W.T) + b
W是一个1*5矩阵,data_X是一个20*5矩阵
WXPlusb矩阵形状=20*5矩阵乘上5*1(W的转置)的矩阵=20*1矩阵
W_derivative += np.dot((WXPlusb - data_Y).T, data_X)
W偏导矩阵形状=1*20矩阵乘上 20*5矩阵=1*5矩阵
b_derivative += np.dot(np.ones(shape=[1, data_X.shape[0]]), WXPlusb - data_Y)
b是一个数,用1*20的全1矩阵乘上20*1矩阵=一个数
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。