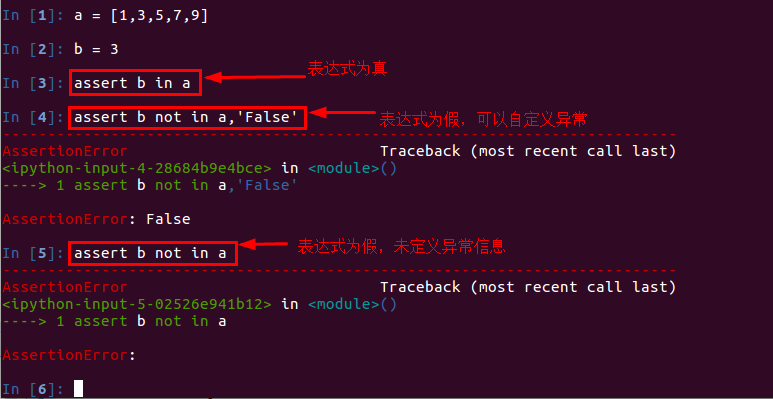
python通过zabbix api获取主机
zabbix强大地方在于有强大的api,zabbix 的api可以拿到zabbix大部分数据,目前我所需的数据基本可以通过api获取,以下是通过zabbix api获取的主机信息python代码,其他数据也如此类推,api使用方法可参见官网文档:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import json
import urllib2
from urllib2 import URLError
from login import zabbix_login
t=zabbix_login()
def hostid_get():
data = json.dumps(
{
"jsonrpc": "2.0",
"method": "host.get",
"params": {
"output": "extend",
"groupids":14,
"filter":{"flags": "4" },
},
"auth":t.user_login(),
"id": 1,
})
request = urllib2.Request(t.url, data)
for key in t.header:
request.add_header(key, t.header[key])
try:
result = urllib2.urlopen(request)
except URLError as e:
if hasattr(e, 'reason'):
print 'zabbix server is faile'
print 'Reason: ', e.reason
elif hasattr(e, 'code'):
print 'zabbix server not request.'
print 'Error code: ', e.code
else:
response = json.loads(result.read())
result.close()
hostid=[]
hostname=[]
for host in response['result']:
hostid.append(host['hostid'])
hostname.append(host['name'])
return hostid,hostname
if __name__ == "__main__":
a,b=hostid_get()
i=0
n=len(b)
for i in range(n):
print a[i],b[i]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。