浅谈pandas用groupby后对层级索引levels的处理方法
层及索引levels,刚开始学习pandas的时候没有太多的操作关于groupby,仅仅是简单的count、sum、size等等,没有更深入的利用groupby后的数据进行处理。近来数据处理的时候有遇到这类问题花了一点时间,所以这里记录以及复习一下:(以下皆是个人实践后的理解)
我使用一个实例来讲解下面的问题:一张数据表中有三列(动物物种、物种品种、品种价格),选出每个物种从大到小品种的前两种,最后只需要品种和价格这两列。

以上这张表是我们后面需要处理的数据表 (物种 品种 价格)
levels:层及索引 (创建pandas类型时可以预先定义;使用groupby后也会生成)
我们看看levels什么样(根据df1物种分类,再根据df2品种排序后 如下图)
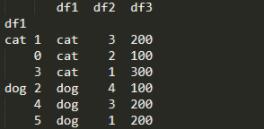
图中可以看出,根据groupby分类后的cat、dog便是level,以及后面的一列原始位置索引也是level
好了现在简单了解levels,我们该如何对它进行处理,如何完成上面的实例呢?(可能你拿到这样的层级数据,不会操作,不知道如何提取其中的信息)
代码及讲解如下:
首先导入pandas、numpy库,以及创建原始数据:
import pandas as pd
import numpy as np
df = pd.DataFrame({'df1':['cat','cat','dog','cat','dog','dog'],'df2':[2,3,4,1,3,1],'df3':[100,200,100,300,200,200]})
原始数据最上面那张图
下面我们根据物种来分类,并且使用apply调用sort_df2函数对品种进行排序:
def sort_df2(data): data = data.sort_values(by='df2',ascending=False) #df2:品种列 ascending:排序方式 return data group = df.groupby(df['df1']).apply(sort_df2) #groupby以及apply的结合使用
处理后数据,上面第二张图
print(group.index) #看看groupby后的行索引什么样

groupby后如上图,有层级标签(这里两列),labels标签(分类,位置)
这里我们需要的是第一层级标签的第一列(也就是cat、dog)
levels = group.index.levels[0] #取出第一级标签:
下面将是两层循环,完成从中选出(物种前两个品种以及它的价格),很简单的操作:
values = [] for i in levels: mid_group = group.loc[i] #选出i标签物种的所有品种 mid_group = mid_group.iloc[:2,:] #我们只取排序后的品种的前两种(要注意这里使用iloc,它与loc的区别) cnt = len(mid_group) #为了防止循环长度错误,所以我们还是需要计算长度,因为如果真正数据不足2条还是不报错 for j in range(cnt): #现在在每个物种cat、dog中操作 value = mid_group.iloc[j,:] #我们选出该物种的第j条所有信息df1、df2、df3 value_pro = (value['df2'],value['df3']) #然后只取df2、df3,将它们放到元组中 values.append(value_pro)
所有的操作完成了,我们看看结果:
print(values) #此时在列表中保存了上面提取的元组信息,我们可以使用pandas再次转换它们为DataFrame,也可以做其它操作
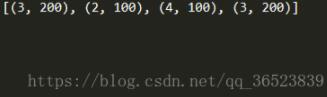
我觉得这个例子比较形象,但是还是有逻辑欠缺的地方,不过不重要,看懂了上面的例子,基本上就能了解和处理层级数据了。当然这里的数据简单,只是为了更好的理解,真正的处理数据时,可能会出现更为复杂的层级结构,这时需要能够更灵活的处理,如果你有更好的理解和建议,可以回复。
-------更新(增加对两层索引的操作)--------
在原来的基础上增加一列df4表示动物的大小特征
df = pd.DataFrame({'df1':['cat','cat','dog','cat','dog','dog'],'df2':[2,3,4,1,3,1],'df3':[100,200,100,300,200,200],'df4':['大','中','小','巨大','小','中']})
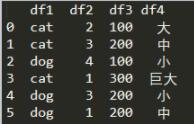
此时根据df1、df4两列来分类,再对两层的层级索引操作:
df_group = df.groupby(['df1','df4']).size()
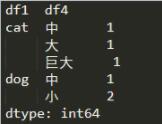
分类后得到的是对应两个特征的动物数量,现在来取得其中的值:
print(df_group.index) h = df_group.loc[['cat','df4']] print(h)
先查看数据的index信息,从中我们可以看到两层索引对应的levels有两中,然后我们根据loc测试选出cat类的df4这一列(也可以填大、中、巨大选出一列)
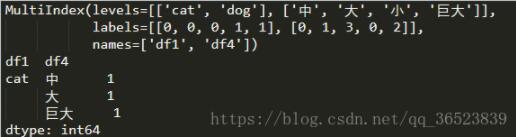
这样就得到了cat种类的信息,当然也可以选出dog种类,那么如何得出(cat,巨大,1)这样的一一对应的数据呢?
df1_name = df_group.index.levels[0] #获得第一层的分类cat、dog
for i in range(len(df1_name)): #循环遍历第一层
df_level = df_group.loc[[df1_name[i],'df4']] #这里是选出第一层的所有信息
df_level_ch = pd.DataFrame(df_level) #由于上面得到是Series我们需要将它转换为DataFrame才能更好的操作
for j in range(len(df_level_ch)): #开始对第二层进行遍历
a = df_level_ch.ix[j].name #由于是DataFrame所以可以取每一行的name值('cat','大')
b = df_level_ch.values[j][0] #获取对应数量,由于是嵌套列表,所以我们逐层获取
print(a,b)
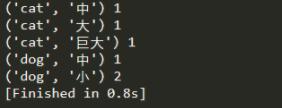
基本上是筛选出来了,还是很简单的。这只是其中的一个例子,如果遇到需要其他的操作,可以根据这个例子来随机变换。
这个方法虽然可以筛选,但是个人觉得数据量过大,就不是很好,暂时没有更好的方法,如果那位朋友有其他操作,可以分享一下。
以上这篇浅谈pandas用groupby后对层级索引levels的处理方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。