对pandas的层次索引与取值的新方法详解
1、层次索引
1.1 定义
在某一个方向拥有多个(两个及两个以上)索引级别,就叫做层次索引。
通过层次化索引,pandas能够以较低维度形式处理高纬度的数据
通过层次化索引,可以按照层次统计数据
层次索引包括Series层次索引和DataFrame层次索引
1.2 Series的层次索引
import numpy as np
import pandas as pd
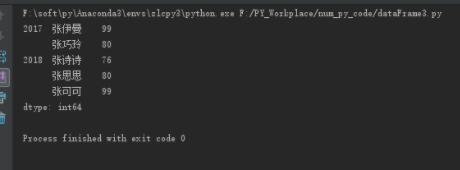
s1 = pd.Series(data=[99, 80, 76, 80, 99],
index=[['2017', '2017', '2018', '2018', '2018'], ['张伊曼', '张巧玲', '张诗诗', '张思思', '张可可']])
print(s1)
1.3 DataFrame的层次索引
# DataFrame的层次索引
df1 = pd.DataFrame({
'year': [2016, 2016, 2017, 2017, 2018],
'fruit': ['apple', 'banana', 'apple', 'banana', 'apple'],
'production': [10, 30, 20, 70, 100],
'profits': [40, 30, 60, 80,10],
})
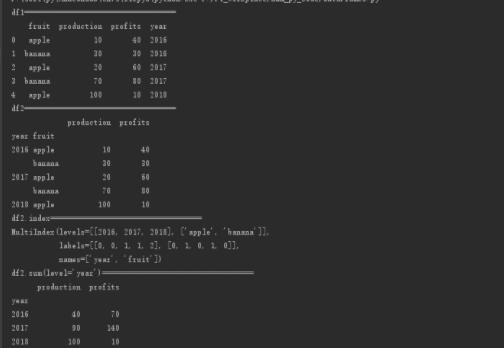
print("df1===================================")
print(df1)
df2 = df1.set_index(['year', 'fruit'])
print("df2===================================")
print(df2)
print("df2.index===================================")
print(df2.index)
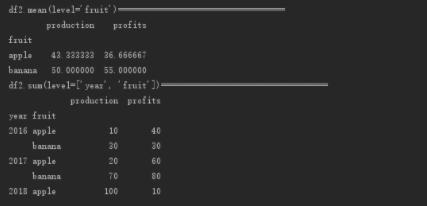
print("df2.sum(level='year')===================================")
print(df2.sum(level='year'))
print("df2.mean(level='fruit')===================================")
print(df2.mean(level='fruit'))
print("df2.sum(level=['year', 'fruit'])===================================")
print(df2.sum(level=['year', 'fruit']))
2、取值的新方法
ix是比较老的方法 新方式是使用iloc loc
iloc 对下标值进行操作 Series与DataFrame都可以操作
loc 对索引值进行操作 Series与DataFrame都可以操作
2.1 Series
# # 取值的新方法
s1 = pd.Series(data=[99, 80, 76, 80, 99],
index=[['2017', '2017', '2018', '2018', '2018'], ['张伊曼', '张巧玲', '张诗诗', '张思思', '张可可']])
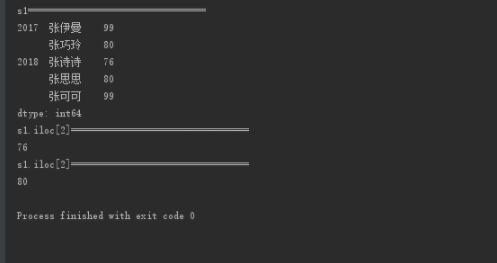
print("s1=================================")
print(s1)
print("s1.iloc[2]=================================")
print(s1.iloc[2])
print("s1.loc['2018']['张思思']=================================")
print(s1.loc['2018']['张思思'])
2.2 DataFrame
df1 = pd.DataFrame({
'year': [2016, 2016, 2017, 2017, 2018],
'fruit': ['apple', 'banana', 'apple', 'banana', 'apple'],
'production': [10, 30, 20, 70, 100],
'profits': [40, 30, 60, 80,10],
})
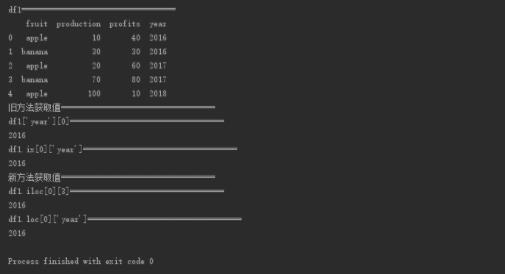
print("df1===================================")
print(df1)
print("旧方法获取值===================================")
print("df1['year'][0]===================================")
print(df1['year'][0])
print("df1.ix[0]['year']===================================")
print(df1.ix[0]['year'])
print("新方法获取值===================================")
print("df1.iloc[0][3]===================================")
print(df1.iloc[0][3])
print("df1.loc[0]['year']===================================")
print(df1.loc[0]['year'])
以上这篇对pandas的层次索引与取值的新方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。