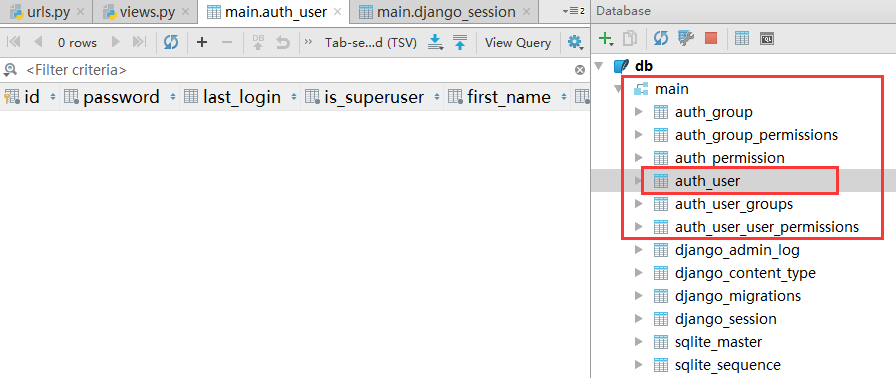
python 不同方式读取文件速度不同的实例
1、按行读取较慢较耗时:
srcFiles = open('inputFile.txt', 'r')
for file_path in srcFiles:
file_path = file_path.rstrip()
2、快速读取所有行:
with open('inputFile.txt', 'r') as fRead:
srcPaths = fRead.readlines() #txt中所有字符串读入list列表srcPaths
random.shuffle(srcPaths) #打乱list顺序
for img_path in srcPaths:
img_path = img_path.rstrip()
以上这篇python 不同方式读取文件速度不同的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。