详解配置Django的Celery异步之路踩坑
人生苦短,我用python。
看到这句话的时候,感觉可能确实是很深得人心,不过每每想学学,就又止步,年纪大了,感觉学什么东西都很慢,很难,精神啊注意力啊思维啊都跟不上。今天奶牛来分享自己今天踩的一个坑。
先说说配置过程吧,初学Django,啥都不懂,当然,python也很水,啥东西都得现查现用。Django安装还是很简单的。
apt-get install python3 pip3 install django
嗯,就是两条命令的事儿。
再说celery的安装:
pip3 install celery pip3 install redis==2.10.6
目前奶牛所在的时间redis for python的版本是redis-3.0.1,为什么要用2.10.6呢?因为3.0.1压根配置就无法运行!!!
继续安装redis server
apt-get install redis service redis start
然后就可以按照celery的官方教程走了,放个URL:http://docs.celeryproject.org/en/latest/django/index.html
python3 manage.py startproject nenew cd nenew python3 manage.py startapp nenewapp touch ./nenew/celery.py touch ./nenewapp/tasks.py
然后增加nenew/nenew/celery.py内容为
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'nenew.settings')
app = Celery('nenew')
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))
增加nenew/nenew/__init__.py的内容
from __future__ import absolute_import, unicode_literals
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)
增加nenew/nenewtest/tasks.py的内容
# Create your tasks here from __future__ import absolute_import, unicode_literals from celery import shared_task @shared_task def add(x, y): return x + y @shared_task def mul(x, y): return x * y @shared_task def xsum(numbers): return sum(numbers)
在nenew/nenew/settings.py中增加和修改
... ALLOWED_HOSTS = ['*'] .... INSTALLED_APPS = [ ... 'nenewtest', ] ... CELERY_BROKER_URL = 'redis://localhost:6379/1' CELERY_RESULT_BACKEND = ‘redis://localhost:6379/0'
在nenew/nenewtest/views.py中增加或修改为
from django.shortcuts import render
from django.http import HttpResponse
from .tasks import add
# Create your views here.
def nenewtest(request):
result = add.delay('2','2')
result.ready()
return HttpResponse('nenew Django Celery worker run !')
最后把views添加到nenew/nenew/urls.py中
from django.contrib import admin
from django.urls import path
from nenewtest import views
urlpatterns = [
path('admin/', admin.site.urls),
path('test/', views.nenewtest),
]
然后在项目目录nenew执行
celery -A nenew worker -l info
这时候worker启动正常会显示:
-------------- <a href="/cdn-cgi/l/email-protection" rel="external nofollow" data-cfemail="2c4f4940495e556c424942495b">[email protected]</a> v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.15.0-39-generic-x86_64-with-Ubuntu-18.04-bionic 2018-11-23 17:31:25
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: nenew:0x7fdc5a155cc0
- ** ---------- .> transport: redis://localhost:6379/1
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 1 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
这样类似的信息,然后我们启动项目,这里需要新开一个shell:
python3 manage.py runserver 0:80
这样我们就可以通过80端口直接访问我们的web了。地址是http://locahost/test
当我们这里访问正常后,在worker界面会有
[2018-11-23 18:09:19,469: INFO/MainProcess] Received task: nenewtest.tasks.add[35faa0fe-dd48-4f8d-9559-516556a93a40]
[2018-11-23 18:09:19,470: INFO/ForkPoolWorker-1] Task nenewtest.tasks.add[35faa0fe-dd48-4f8d-9559-516556a93a40] succeeded in 0.00031037399821798317s: '22'
如下语句表示执行成功,这样子就表示通过Django的网页我们对celery任务的异步执行成功。
当然,按照我的方法是可以一步成功的,因为奶牛已经踩了一整天的坑了,被一个错误郁闷得不要不要的。
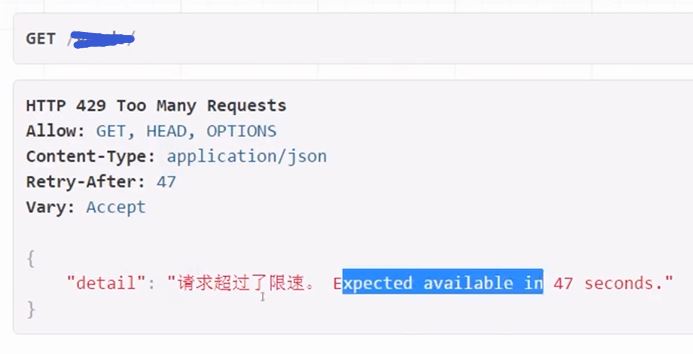
AttributeError: 'float' object has no attribute 'items'
就是这个错误,查遍国内的所有网站都没有结果,然后就去bing的国际版查,然后发现果然是有bug在啊,奶牛这一天浪费得可真是够了。
这是celery的一个issue,在地址https://github.com/celery/celery/issues/5175 ,issue里面提及在2018/11/22日 it's fixed in kombu and celery master。问题的根源是celery对redis3的支持不好,补救方法是
Solution: Roll back redis with pip: pip install redis==2.10.6
然后在commit里面找到是对requirements/extras/redis.txt文件进行版本限定。
-redis>=2.10.5 +redis>=2.10.5,<3
好了,踩坑总算结束了。毕竟是新手,很多问题可能就是潜意识认为是自己的代码有问题,实际。。。实际可能并不是这样子,得多关注源码的更迭和问题处理才好。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。