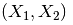Python基于聚类算法实现密度聚类(DBSCAN)计算【测试可用】
本文实例讲述了Python基于聚类算法实现密度聚类(DBSCAN)计算。分享给大家供大家参考,具体如下:
算法思想
基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果。
几个必要概念:
ε-邻域:对于样本集中的xj, 它的ε-邻域为样本集中与它距离小于ε的样本所构成的集合。
核心对象:若xj的ε-邻域中至少包含MinPts个样本,则xj为一个核心对象。
密度直达:若xj位于xi的ε-邻域中,且xi为核心对象,则xj由xi密度直达。
密度可达:若样本序列p1, p2, ……, pn。pi+1由pi密度直达,则p1由pn密度可达。
大致思想如下:
1. 初始化核心对象集合T为空,遍历一遍样本集D中所有的样本,计算每个样本点的ε-邻域中包含样本的个数,如果个数大于等于MinPts,则将该样本点加入到核心对象集合中。初始化聚类簇数k = 0, 初始化未访问样本集和为P = D。
2. 当T集合中存在样本时执行如下步骤:
- 2.1记录当前未访问集合P_old = P
- 2.2从T中随机选一个核心对象o,初始化一个队列Q = [o]
- 2.3P = P-o(从T中删除o)
- 2.4当Q中存在样本时执行:
- 2.4.1取出队列中的首个样本q
- 2.4.2计算q的ε-邻域中包含样本的个数,如果大于等于MinPts,则令S为q的ε-邻域与P的交集,
Q = Q+S, P = P-S
- 2.5 k = k + 1,生成聚类簇为Ck = P_old - P
- 2.6 T = T - Ck
3. 划分为C= {C1, C2, ……, Ck}
Python代码实现
#-*- coding:utf-8 -*-
import math
import numpy as np
import pylab as pl
#数据集:每三个是一组分别是西瓜的编号,密度,含糖量
data = """
1,0.697,0.46,2,0.774,0.376,3,0.634,0.264,4,0.608,0.318,5,0.556,0.215,
6,0.403,0.237,7,0.481,0.149,8,0.437,0.211,9,0.666,0.091,10,0.243,0.267,
11,0.245,0.057,12,0.343,0.099,13,0.639,0.161,14,0.657,0.198,15,0.36,0.37,
16,0.593,0.042,17,0.719,0.103,18,0.359,0.188,19,0.339,0.241,20,0.282,0.257,
21,0.748,0.232,22,0.714,0.346,23,0.483,0.312,24,0.478,0.437,25,0.525,0.369,
26,0.751,0.489,27,0.532,0.472,28,0.473,0.376,29,0.725,0.445,30,0.446,0.459"""
#数据处理 dataset是30个样本(密度,含糖量)的列表
a = data.split(',')
dataset = [(float(a[i]), float(a[i+1])) for i in range(1, len(a)-1, 3)]
#计算欧几里得距离,a,b分别为两个元组
def dist(a, b):
return math.sqrt(math.pow(a[0]-b[0], 2)+math.pow(a[1]-b[1], 2))
#算法模型
def DBSCAN(D, e, Minpts):
#初始化核心对象集合T,聚类个数k,聚类集合C, 未访问集合P,
T = set(); k = 0; C = []; P = set(D)
for d in D:
if len([ i for i in D if dist(d, i) <= e]) >= Minpts:
T.add(d)
#开始聚类
while len(T):
P_old = P
o = list(T)[np.random.randint(0, len(T))]
P = P - set(o)
Q = []; Q.append(o)
while len(Q):
q = Q[0]
Nq = [i for i in D if dist(q, i) <= e]
if len(Nq) >= Minpts:
S = P & set(Nq)
Q += (list(S))
P = P - S
Q.remove(q)
k += 1
Ck = list(P_old - P)
T = T - set(Ck)
C.append(Ck)
return C
#画图
def draw(C):
colValue = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in range(len(C)):
coo_X = [] #x坐标列表
coo_Y = [] #y坐标列表
for j in range(len(C[i])):
coo_X.append(C[i][j][0])
coo_Y.append(C[i][j][1])
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i%len(colValue)], label=i)
pl.legend(loc='upper right')
pl.show()
C = DBSCAN(dataset, 0.11, 5)
draw(C)
本机测试运行结果图:

更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。