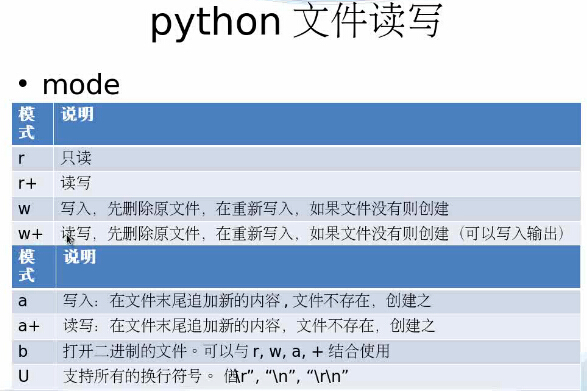
pyspark操作MongoDB的方法步骤
如何导入数据
数据可能有各种格式,虽然常见的是HDFS,但是因为在Python爬虫中数据库用的比较多的是MongoDB,所以这里会重点说说如何用spark导入MongoDB中的数据。
当然,首先你需要在自己电脑上安装spark环境,简单说下,在这里下载spark,同时需要配置好JAVA,Scala环境。
这里建议使用Jupyter notebook,会比较方便,在环境变量中这样设置
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark
如果你的环境中有多个Python版本,同样可以制定你想要使用的解释器,我这里是python36,根据需求修改。
PYSPARK_PYTHON=/usr/bin/python36
pyspark对mongo数据库的基本操作 (๑• . •๑)
有几点需要注意的:
- 不要安装最新的pyspark版本,请安装
pip3 install pyspark==2.3.2 -
spark-connector与平常的MongoDB写法不同,格式是:mongodb://127.0.0.1:database.collection - 如果计算数据量比较大,你的电脑可能会比较卡,^_^
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@author: zhangslob
@file: spark_count.py
@time: 2019/01/03
@desc:
不要安装最新的pyspark版本
`pip3 install pyspark==2.3.2`
更多pyspark操作MongoDB请看https://docs.mongodb.com/spark-connector/master/python-api/
"""
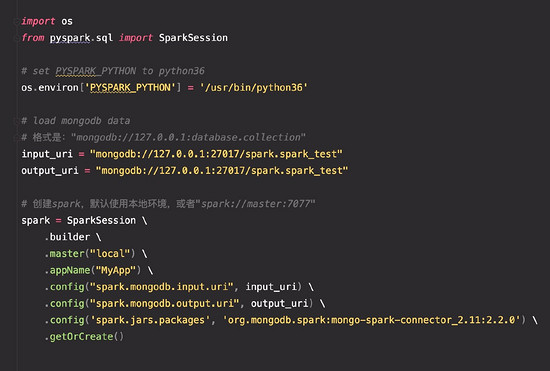
import os
from pyspark.sql import SparkSession
# set PYSPARK_PYTHON to python36
os.environ['PYSPARK_PYTHON'] = '/usr/bin/python36'
# load mongodb data
# 格式是:"mongodb://127.0.0.1:database.collection"
input_uri = "mongodb://127.0.0.1:27017/spark.spark_test"
output_uri = "mongodb://127.0.0.1:27017/spark.spark_test"
# 创建spark,默认使用本地环境,或者"spark://master:7077"
spark = SparkSession \
.builder \
.master("local") \
.appName("MyApp") \
.config("spark.mongodb.input.uri", input_uri) \
.config("spark.mongodb.output.uri", output_uri) \
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.11:2.2.0') \
.getOrCreate()
def except_id(collection_1, collection_2, output_collection, pipeline):
"""
计算表1与表2中不同的数据
:param collection_1: 导入表1
:param collection_2: 导入表2
:param output_collection: 保存的表
:param pipeline: MongoDB查询语句 str
:return:
"""
# 可以在这里指定想要导入的数据库,将会覆盖上面配置中的input_uri。下面保存数据也一样
# .option("collection", "mongodb://127.0.0.1:27017/spark.spark_test")
# .option("database", "people").option("collection", "contacts")
df_1 = spark.read.format('com.mongodb.spark.sql.DefaultSource').option("collection", collection_1) \
.option("pipeline", pipeline).load()
df_2 = spark.read.format('com.mongodb.spark.sql.DefaultSource').option("collection", collection_2) \
.option("pipeline", pipeline).load()
# df_1有但是不在 df_2,同理可以计算df_2有,df_1没有
df = df_1.subtract(df_2)
df.show()
# mode 参数可选范围
# * `append`: Append contents of this :class:`DataFrame` to existing data.
# * `overwrite`: Overwrite existing data.
# * `error` or `errorifexists`: Throw an exception if data already exists.
# * `ignore`: Silently ignore this operation if data already exists.
df.write.format("com.mongodb.spark.sql.DefaultSource").option("collection", output_collection).mode("append").save()
spark.stop()
if __name__ == '__main__':
# mongodb query, MongoDB查询语句,可以减少导入数据量
pipeline = "[{'$project': {'uid': 1, '_id': 0}}]"
collection_1 = "spark_1"
collection_2 = "spark_2"
output_collection = 'diff_uid'
except_id(collection_1, collection_2, output_collection, pipeline)
print('success')
完整代码地址: spark_count_diff_uid.py
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。