使用python实现语音文件的特征提取方法
概述
语音识别是当前人工智能的比较热门的方向,技术也比较成熟,各大公司也相继推出了各自的语音助手机器人,如百度的小度机器人、阿里的天猫精灵等。语音识别算法当前主要是由RNN、LSTM、DNN-HMM等机器学习和深度学习技术做支撑。但训练这些模型的第一步就是将音频文件数据化,提取当中的语音特征。
MP3文件转化为WAV文件
录制音频文件的软件大多数都是以mp3格式输出的,但mp3格式文件对语音的压缩比例较重,因此首先利用ffmpeg将转化为wav原始文件有利于语音特征的提取。其转化代码如下:
from pydub import AudioSegment import pydub def MP32WAV(mp3_path,wav_path): """ 这是MP3文件转化成WAV文件的函数 :param mp3_path: MP3文件的地址 :param wav_path: WAV文件的地址 """ pydub.AudioSegment.converter = "D:\\ffmpeg\\bin\\ffmpeg.exe" MP3_File = AudioSegment.from_mp3(file=mp3_path) MP3_File.export(wav_path,format="wav")
读取WAV语音文件,对语音进行采样
利用wave库对语音文件进行采样。
代码如下:
import wave
import json
def Read_WAV(wav_path):
"""
这是读取wav文件的函数,音频数据是单通道的。返回json
:param wav_path: WAV文件的地址
"""
wav_file = wave.open(wav_path,'r')
numchannel = wav_file.getnchannels() # 声道数
samplewidth = wav_file.getsampwidth() # 量化位数
framerate = wav_file.getframerate() # 采样频率
numframes = wav_file.getnframes() # 采样点数
print("channel", numchannel)
print("sample_width", samplewidth)
print("framerate", framerate)
print("numframes", numframes)
Wav_Data = wav_file.readframes(numframes)
Wav_Data = np.fromstring(Wav_Data,dtype=np.int16)
Wav_Data = Wav_Data*1.0/(max(abs(Wav_Data))) #对数据进行归一化
# 生成音频数据,ndarray不能进行json化,必须转化为list,生成JSON
dict = {"channel":numchannel,
"samplewidth":samplewidth,
"framerate":framerate,
"numframes":numframes,
"WaveData":list(Wav_Data)}
return json.dumps(dict)
绘制声波折线图与频谱图
代码如下:
from matplotlib import pyplot as plt def DrawSpectrum(wav_data,framerate): """ 这是画音频的频谱函数 :param wav_data: 音频数据 :param framerate: 采样频率 """ Time = np.linspace(0,len(wav_data)/framerate*1.0,num=len(wav_data)) plt.figure(1) plt.plot(Time,wav_data) plt.grid(True) plt.show() plt.figure(2) Pxx, freqs, bins, im = plt.specgram(wav_data,NFFT=1024,Fs = 16000,noverlap=900) plt.show() print(Pxx) print(freqs) print(bins) print(im)
首先利用百度AI开发平台的语音合API生成的MP3文件进行上述过程的结果。
声波折线图
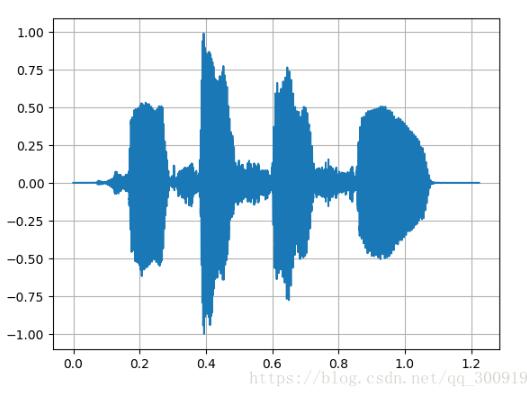
频谱图
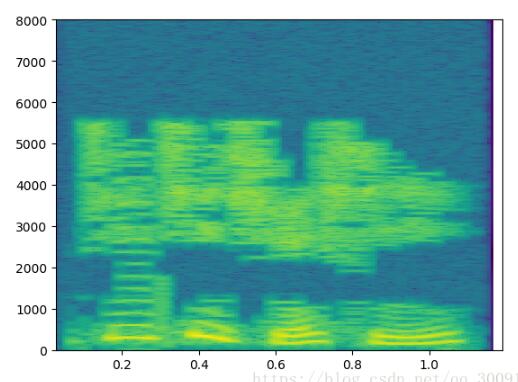
全部代码
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2018/7/5 13:11
# @Author : DaiPuwei
# @FileName: VoiceExtract.py
# @Software: PyCharm
# @E-mail :771830171@qq.com
# @Blog :https://blog.csdn.net/qq_30091945
import numpy as np
from pydub import AudioSegment
import pydub
import os
import wave
import json
from matplotlib import pyplot as plt
def MP32WAV(mp3_path,wav_path):
"""
这是MP3文件转化成WAV文件的函数
:param mp3_path: MP3文件的地址
:param wav_path: WAV文件的地址
"""
pydub.AudioSegment.converter = "D:\\ffmpeg\\bin\\ffmpeg.exe" #说明ffmpeg的地址
MP3_File = AudioSegment.from_mp3(file=mp3_path)
MP3_File.export(wav_path,format="wav")
def Read_WAV(wav_path):
"""
这是读取wav文件的函数,音频数据是单通道的。返回json
:param wav_path: WAV文件的地址
"""
wav_file = wave.open(wav_path,'r')
numchannel = wav_file.getnchannels() # 声道数
samplewidth = wav_file.getsampwidth() # 量化位数
framerate = wav_file.getframerate() # 采样频率
numframes = wav_file.getnframes() # 采样点数
print("channel", numchannel)
print("sample_width", samplewidth)
print("framerate", framerate)
print("numframes", numframes)
Wav_Data = wav_file.readframes(numframes)
Wav_Data = np.fromstring(Wav_Data,dtype=np.int16)
Wav_Data = Wav_Data*1.0/(max(abs(Wav_Data))) #对数据进行归一化
# 生成音频数据,ndarray不能进行json化,必须转化为list,生成JSON
dict = {"channel":numchannel,
"samplewidth":samplewidth,
"framerate":framerate,
"numframes":numframes,
"WaveData":list(Wav_Data)}
return json.dumps(dict)
def DrawSpectrum(wav_data,framerate):
"""
这是画音频的频谱函数
:param wav_data: 音频数据
:param framerate: 采样频率
"""
Time = np.linspace(0,len(wav_data)/framerate*1.0,num=len(wav_data))
plt.figure(1)
plt.plot(Time,wav_data)
plt.grid(True)
plt.show()
plt.figure(2)
Pxx, freqs, bins, im = plt.specgram(wav_data,NFFT=1024,Fs = 16000,noverlap=900)
plt.show()
print(Pxx)
print(freqs)
print(bins)
print(im)
def run_main():
"""
这是主函数
"""
# MP3文件和WAV文件的地址
path1 = './MP3_File'
path2 = "./WAV_File"
paths = os.listdir(path1)
mp3_paths = []
# 获取mp3文件的相对地址
for mp3_path in paths:
mp3_paths.append(path1+"/"+mp3_path)
print(mp3_paths)
# 得到MP3文件对应的WAV文件的相对地址
wav_paths = []
for mp3_path in mp3_paths:
wav_path = path2+"/"+mp3_path[1:].split('.')[0].split('/')[-1]+'.wav'
wav_paths.append(wav_path)
print(wav_paths)
# 将MP3文件转化成WAV文件
for(mp3_path,wav_path) in zip(mp3_paths,wav_paths):
MP32WAV(mp3_path,wav_path)
for wav_path in wav_paths:
Read_WAV(wav_path)
# 开始对音频文件进行数据化
for wav_path in wav_paths:
wav_json = Read_WAV(wav_path)
print(wav_json)
wav = json.loads(wav_json)
wav_data = np.array(wav['WaveData'])
framerate = int(wav['framerate'])
DrawSpectrum(wav_data,framerate)
if __name__ == '__main__':
run_main()
以上这篇使用python实现语音文件的特征提取方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。
