Pycharm+Scrapy安装并且初始化项目的方法
前言
Scrapy是一个开源的网络爬虫框架,Python编写的。最初设计用于网页抓取,也可以用来提取数据使用API或作为一个通用的网络爬虫。是数据采集不可必备的利器。
安装
pip install scrapy
如果使用上面的命令太慢。国内可以使用豆瓣源进行加速。
pip install -i https://pypi.douban.com/simple scrapy
注意要写错了,是 https://pypi.douban.com/simple 很多包都可以使用这个源进行加速,这也是pip的一个技巧,还可以使用阿里云进行加速。
安装完成之后在命令行输入
scrapy -v
如果出现了相应的版本号就说明安装成功。
创建项目
目前还没有IDE 能够创建scrapy的项目,我们必须手动初始化项目。
1、找一个目录
输入命令
scrapy startproject SpiderObject
命令行出现这样的结果说明创建成果
You can start your first spider with: cd SpiderObject scrapy genspider example example.com
去文件夹中看看

初始化项目
使用pycharm打开该项目
如果出现这个页面就说明对了。
下面生成一个模板
打开pycharm的terminal
输入
scrapy genspider BiduSpider http://www.baidu.com
我们的spider 包下面会多一个文件
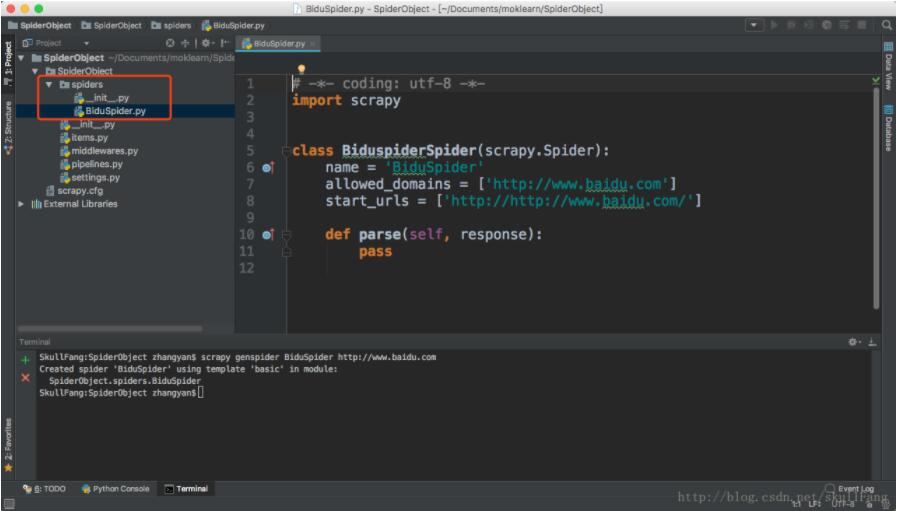
这说明我们的spider创建成功。可以在pytharm中使用这个 强大的框架了。
以上这篇Pycharm+Scrapy安装并且初始化项目的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。
