python广度优先搜索得到两点间最短路径
前言
之前一直写不出来,这周周日花了一下午终于弄懂了, 顺便放博客里,方便以后忘记了再看看。
要实现的是输入一张 图,起点,终点,输出起点和终点之间的最短路径。
广度优先搜索
适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快
复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数
思路
广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索;
比如下图:
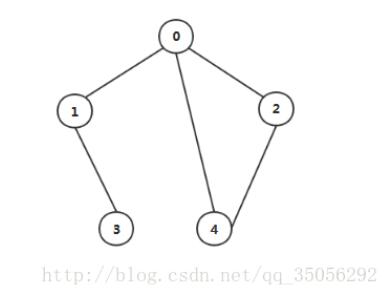
从0结点开始搜索的话,一开始是0、将0加入队列中;
然后下一层,0可以到达的有1,2,4,将他们加入队列中;
接下来是1,1能到达的且未被访问的是结点3
顺序就是 0, 1,2,4, 3,这里用下划线表示每一层搜索得到的结点;
每一次用cur = que[head]取出头指针指向的结点,并搜索它能到达的结点;因此,可以用一个队列que来保存已经访问过的结点,队列有头指针head以及尾指针tail,起点start与结点i有边并且结点i未被访问过,则将该结点加入队列中,tail指针往后移动;当tail等于顶点数时算法结束
对于每一次while循环,head都加一,也就是往右边移动,比如一开始head位置是0,下一层的时候head位置元素就为1,也就是搜索与结点1有边的且未被访问的结点
用一个数组book来标识结点i是否已经被访问过;用字典来保存起点到各个点的最短路径;
代码如下:
import numpy as np
ini_matrix = [
[0, 1, 1, 0, 1],
[1, 0, 0, 1, 0],
[1, 0, 0, 0, 1],
[0, 1, 0, 0, 0],
[1, 0, 1, 0, 0]
]
def bfs(matrix_para, start_point_para, end_point_para):
"""
广度优先搜索
:param matrix_para 图
:param start_point_para 起点
:param end_point_para 终点
:return: 返回关联度
"""
matrix = matrix_para
start_point = start_point_para
end_point = end_point_para
vertex_num = len(matrix) # 顶点个数
que = np.zeros(vertex_num, dtype=np.int) # 队列, 用于存储遍历过的顶点
book = np.zeros(vertex_num, dtype=np.int) # 标记顶点i是否已经被访问,1表被访问,0表未被访问
point_step_dict = dict() # key:点,value:起点到该点的步长
# 队列初始化
head = 0
tail = 0
# 从起点出发,将起点加入队列
que[tail] = start_point # 等号右边为顶点号(起点)
tail += 1
book[start_point] = 1 # book[i] i为顶点号
while head<tail:
cur = que[head]
for i in range(vertex_num):
# 判断从顶点cur到顶点i是否有边,并判断顶点i是否已经被访问过
if matrix[cur][i] == 1 and book[i] == 0:
que[tail] = i # 将顶点i放入队列中
tail += 1 # tail指针往后移
book[i] = 1 # 标记顶点i为已经访问过
point_step_dict[i] = head + 1 # 记录步长
if tail == vertex_num: # 说明所有顶点都被访问过
break
head += 1
for i in range(tail):
print(que[i])
try:
relevancy = point_step_dict[end_point]
return relevancy
except KeyError: # 捕获错误,如果起点不能到达end_point,则字典里没有这个键,返回None
return None
result = bfs(ini_matrix, 1, 4)
print("result:", result)
错误
在经同学的一番调教之后,我深刻意识到了这段代码有个问题(不能用head记录步长),就是对于有环的时候,可能得到的步长(迭代次数)会比最短路径还大;
比如,起点为4,终点为3:这里每一遍迭代都是一次while循环
第一遍迭代,队列4,head指向4,步长为0
第二遍迭代,队列4,0 , 2,head指向0, 步长为1
第三遍迭代,队列4,0 , 2,1,head指向2,步长为2,
第四遍迭代,对于2,2周围都被访问过了,但此时head仍然+=1为3,这就导致了下一次的步长会比实际的步长多1
第五遍迭代, 3,步长为4
纠正
改进的思路:用count记录步长,flag用于标识当前搜索能到达的边的该结点cur = que[head]周围是否已经被访问过,False表示没有,True表示该结点i周围都被访问过了;也就是,当flag为False时,表示对于cur周围已经都访问过了,此时步长count不需要自增1;
import numpy as np
ini_matrix = [
[0, 1, 1, 0, 1],
[1, 0, 0, 1, 0],
[1, 0, 0, 0, 1],
[0, 1, 0, 0, 0],
[1, 0, 1, 0, 0]
]
def bfs(matrix_para, start_point_para, end_point_para):
"""
广度优先搜索
:param matrix_para 图
:param start_point_para 起点
:param end_point_para 终点
:return: 返回关联度
"""
matrix = matrix_para
start_point = start_point_para
end_point = end_point_para
vertex_num = len(matrix) # 顶点个数
que = np.zeros(vertex_num, dtype=np.int) # 队列, 用于存储遍历过的顶点
book = np.zeros(vertex_num, dtype=np.int) # 标记顶点i是否已经被访问,1表被访问,0表未被访问
point_step_dict = dict() # key:点,value:起点到该点的步长
# 队列初始化
head = 0
tail = 0
# 迭代次数
count = 0
# 从0号顶点出发,将0号顶点加入队列
que[tail] = start_point # 等号右边为顶点号(起点)
tail += 1
book[start_point] = 1 # book[i] i为顶点号
while head<tail:
flag = False # 用flag标识结点i是否周围都是被访问过的
cur = que[head]
for i in range(vertex_num):
# 判断从顶点cur到顶点i是否有边,并判断顶点i是否已经被访问过
if matrix[cur][i] == 1 and book[i] == 0:
que[tail] = i # 将顶点i放入队列中
tail += 1 # tail指针往后移
book[i] = 1 # 标记顶点i为已经访问过
point_step_dict[i] = count + 1 # 记录步长
flag = True
if tail == vertex_num: # 说明所有顶点都被访问过
break
if flag:
count += 1
head += 1
for i in range(tail):
print(que[i])
try:
relevancy = point_step_dict[end_point]
return relevancy
except KeyError:
return None
result = bfs(ini_matrix, 3, 4)
print("result:", result)
写在后面
真的很抱歉, 第一次写这种算法博客结果出了这么大的问题,之前都是一些记录BUG的文章,还好同学及时和我说了,主要原因还是自己没有做那么多测试的问题。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。