Python字典的核心底层原理讲解
字典对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组),数组的每个单元叫做 bucket。每个 bucket 有两部分:一个是键对象的引用,一个是值对象的引用。所有 bucket 结构和大小一致,我们可以通过偏移量来读取指定 bucket。下面通过存储与获取数据的过程介绍字典的底层原理。
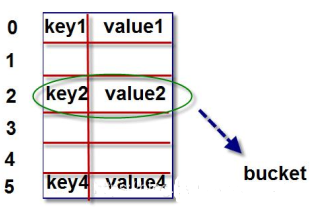
存储数据的过程
例如,我们将‘name' = ‘张三' 这个键值对存储到字典map中,假设数组长度为8,可以用3位二进制表示。
>>> map = {}
>>> map
{}
>>> map['name'] = '张三'
1、计算name的散列值。
>>> bin(hash('name'))
'0b101011100000110111101000101010100010011010110010100101001000110'
2、用散列值的最右边 3 位数字作为偏移量,即“110”,十进制是数字 6。我们查看偏移量 6,对应的 bucket 是否为空。如果为空,则将键值对放进去。如果不为空,则依次取右移 3 位作为偏移量,即“000”,十进制是数字0,循环此过程,直到找到为空的 bucket 将键值对放进去。python 会根据散列表的拥挤程度扩容。“扩容”指的是:创造更大的数组,将原有内容拷贝到新数组中。接近 2/3 时,数组就会扩容。扩容后,偏移量的数字个数增加,如数组长度扩容到16时,可以用最右边4位数字作为偏移量。
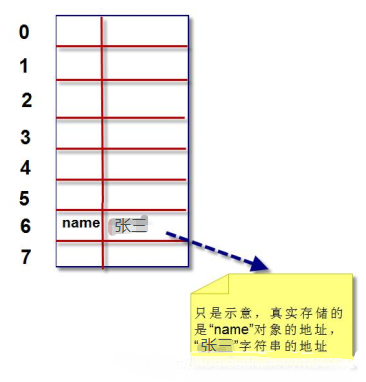
获取数据的过程
>>> map.get('name')
'张三'
1、计算name的散列值
2、用最右边 3 位数字作为偏移量,即“110”,十进制是数字6。查看偏移量 6,对应的 bucket 是否为空。如果为空,则返回 None。如果不为空,则将这个 bucket 的键对象计算对应散列值,和我们的散列值进行比较,如果相等,则将对应“值对象”返回;如果不相等,则再依次取其他几位数字,重新计算偏移量。循环此过程。
小结:
1.键必须可散列,如数字、元组、字符串;自定义对象需要满足支持hash、支持通过__eq__()方法检测相等性、若 a==b 为真,则 hash(a)==hash(b)也为真。
>>> b = [1,2] //List不可散列 >>> bin(hash(b)) Traceback (most recent call last): File "<pyshell#90>", line 1, in <module> bin(hash(b)) TypeError: unhashable type: 'list'
2. 字典在内存中开销巨大,典型的空间换时间;
3. 键查询速度很快;
4. 往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字典的同时进行字典的修改。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接