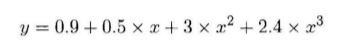对DataFrame数据中的重复行,利用groupby累加合并的方法详解
pandas读取一组数据,可能存在重复索引,虽然可以利用drop_duplicate直接删除,但是会删除重要信息。
比如同一ID用户,多次登录学习时间。要计算该用户总共‘'学习时间‘',就要把重复的ID的‘'学习时间‘'累加。
可以结合groupby和sum函数完成该操作。
实例如下:
新建一个DataFrame,计算每个 id 的总共学习时间。其中 id 为one/two的存在重复学习时间。先利用 groupby 按照键 id 分组,然后利用sum()函数求和,即可得到每个id的总共学习时间。

以上这篇对DataFrame数据中的重复行,利用groupby累加合并的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。