python实现词法分析器
简单Python词法分析器实现,供大家参考,具体内容如下
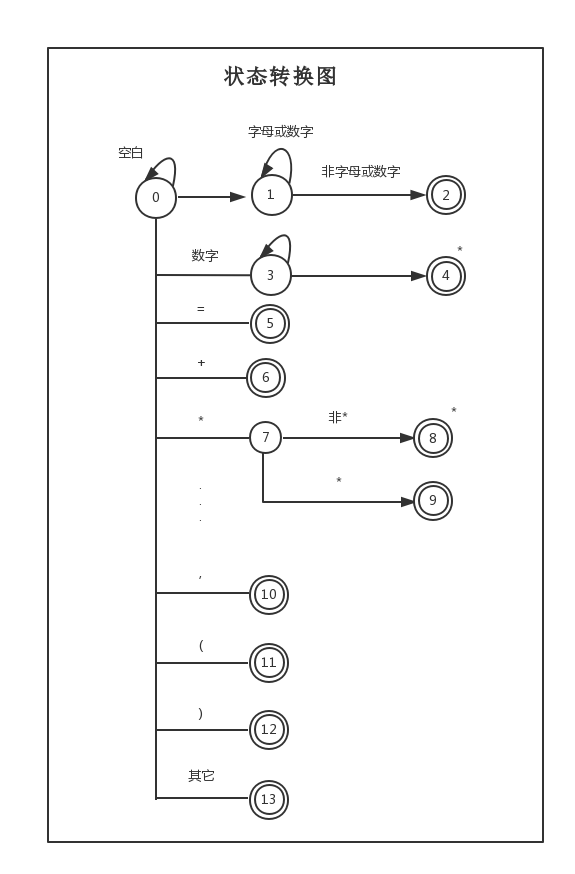
词法分析器状态转换图:
词法分析器总流程图:

预处理程序:

词法分析器:

词法分析器程序详细设计

详细代码实现:
#!/usr/bin/env python3.4
# coding=utf-8
import sys
import string
keywards = {}
# 关键字部分
keywards['False'] = 101
keywards['class'] = 102
keywards['finally'] = 103
keywards['is'] = 104
keywards['return'] = 105
keywards['None'] = 106
keywards['continue'] = 107
keywards['for'] = 108
keywards['lambda'] = 109
keywards['try'] = 110
keywards['True'] = 111
keywards['def'] = 112
keywards['from'] = 113
keywards['nonlocal'] = 114
keywards['while'] = 115
keywards['and'] = 116
keywards['del'] = 117
keywards['global'] = 118
keywards['not'] = 119
keywards['with'] = 120
keywards['as'] = 121
keywards['elif'] = 122
keywards['if'] = 123
keywards['or'] = 124
keywards['yield'] = 125
keywards['assert'] = 126
keywards['else'] = 127
keywards['import'] = 128
keywards['pass'] = 129
keywards['break'] = 130
keywards['except'] = 131
keywards['in'] = 132
keywards['raise'] = 133
# 符号
keywards['+'] = 201
keywards['-'] = 202
keywards['*'] = 203
keywards['/'] = 204
keywards['='] = 205
keywards[':'] = 206
keywards['<'] = 207
keywards['>'] = 208
keywards['%'] = 209
keywards['&'] = 210
keywards['!'] = 211
keywards['('] = 212
keywards[')'] = 213
keywards['['] = 214
keywards[']'] = 215
keywards['{'] = 216
keywards['}'] = 217
keywards['#'] = 218
keywards['|'] = 219
keywards[','] = 220
# 变量
# keywards['var'] = 301
# 常量
# keywards['const'] = 401
# Error
# keywards['const'] = 501
signlist = {}
# 预处理函数,将文件中的空格,换行等无关字符处理掉
def pretreatment(file_name):
try:
fp_read = open(file_name, 'r')
fp_write = open('file.tmp', 'w')
sign = 0
while True:
read = fp_read.readline()
if not read:
break
length = len(read)
i = -1
while i < length - 1:
i += 1
if sign == 0:
if read[i] == ' ':
continue
if read[i] == '#':
break
elif read[i] == ' ':
if sign == 1:
continue
else:
sign = 1
fp_write.write(' ')
elif read[i] == '\t':
if sign == 1:
continue
else:
sign = 1
fp_write.write(' ')
elif read[i] == '\n':
if sign == 1:
continue
else:
fp_write.write(' ')
sign = 1
elif read[i] == '"':
fp_write.write(read[i])
i += 1
while i < length and read[i] != '"':
fp_write.write(read[i])
i += 1
if i >= length:
break
fp_write.write(read[i])
elif read[i] == "'":
fp_write.write(read[i])
i += 1
while i < length and read[i] != "'":
fp_write.write(read[i])
i += 1
if i >= length:
break
fp_write.write(read[i])
else:
sign = 3
fp_write.write(read[i])
except Exception:
print(file_name, ': This FileName Not Found!')
def save(string):
if string in keywards.keys():
if string not in signlist.keys():
signlist[string] = keywards[string]
else:
try:
float(string)
save_const(string)
except ValueError:
save_var(string)
def save_var(string):
if string not in signlist.keys():
if len(string.strip()) < 1:
pass
else:
if is_signal(string) == 1:
signlist[string] = 301
else:
signlist[string] = 501
def save_const(string):
if string not in signlist.keys():
signlist[string] = 401
def save_error(string):
if string not in signlist.keys():
signlist[string] = 501
def is_signal(s):
if s[0] == '_' or s[0] in string.ascii_letters:
for i in s:
if i in string.ascii_letters or i == '_' or i in string.digits:
pass
else:
return 0
return 1
else:
return 0
def recognition(filename):
try:
fp_read = open(filename, 'r')
string = ""
sign = 0
while True:
read = fp_read.read(1)
if not read:
break
if read == ' ':
if len(string.strip()) < 1:
sign = 0
pass
else:
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
sign = 0
elif read == '(':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save('(')
elif read == ')':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save(')')
elif read == '[':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save('[')
elif read == ']':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save(']')
elif read == '{':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save('{')
elif read == '}':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save('}')
elif read == '<':
save(string)
string = ""
save('<')
elif read == '>':
save(string)
string = ""
save('>')
elif read == ',':
save(string)
string = ""
save(',')
elif read == "'":
string += read
if sign == 1:
sign = 0
save_const(string)
string = ""
else:
if sign != 2:
sign = 1
elif read == '"':
string += read
if sign == 2:
sign = 0
save_const(string)
string = ""
else:
if sign != 1:
sign = 2
elif read == ':':
if sign == 1 or sign == 2:
string += read
else:
save(string)
string = ""
save(':')
elif read == '+':
save(string)
string = ""
save('+')
elif read == '=':
save(string)
string = ""
save('=')
else:
string += read
except Exception as e:
print(e)
def main():
if len(sys.argv) < 2:
print("Please Input FileName")
else:
pretreatment(sys.argv[1])
recognition('file.tmp')
for i in signlist.keys():
print("(", signlist[i], ",", i, ")")
if __name__ == '__main__':
main()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。