浅谈pandas筛选出表中满足另一个表所有条件的数据方法
今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据。例如:
list1 结构:名字,ID,颜色,数量,类型。
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']]
list2结构:名字,类型,颜色。
list2 = [['a','03',255],['a','06',481]]
如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:list = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03']]。
首先将两个list转化为dataframe.
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"])
数据结构如下:

然后利用pandas.merge函数将其进行内连接。
这个函数的语法是:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)。这函数连接方式和sql的连接类似,由参数how来控制。
最后的代码如下:
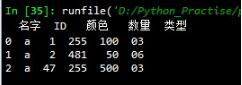
import pandas as pd list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"]) df=pd.merge(df1,df2,how='inner',on=["名字","类型","颜色"],right_index=True) df.sort_index(inplace=True) print(df)
返回结果按照左表的顺序输出:
以上这篇浅谈pandas筛选出表中满足另一个表所有条件的数据方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。