对pandas处理json数据的方法详解
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe。
先拿出我要处理的json字符串:
strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
pandas.read_json的语法如下:
pandas.read_json(path_or_buf=None, orient=None, typ='frame', dtype=True, convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None, compression='infer')
第一参数就是json文件路径或者json格式的字符串。
第二参数orient是表明预期的json字符串格式。orient的设置有以下几个值:
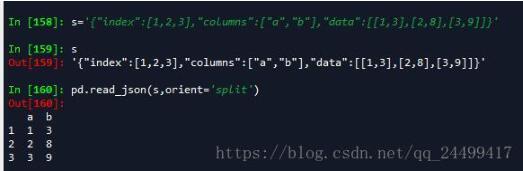
(1).'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
这种就是有索引,有列字段,和数据矩阵构成的json格式。key名称只能是index,columns和data。
'records' : list like [{column -> value}, ... , {column -> value}]
这种就是成员为字典的列表。如我今天要处理的json数据示例所见。构成是列字段为键,值为键值,每一个字典成员就构成了dataframe的一行数据。
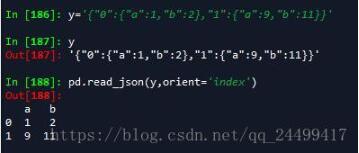
'index' : dict like {index -> {column -> value}}
以索引为key,以列字段构成的字典为键值。如:
'columns' : dict like {column -> {index -> value}}
这种处理的就是以列为键,对应一个值字典的对象。这个字典对象以索引为键,以值为键值构成的json字符串。如下图所示:
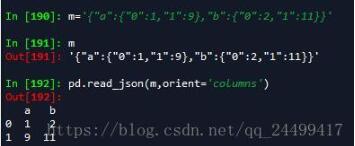
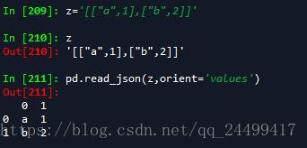
'values' : just the values array。
values这种我们就很常见了。就是一个嵌套的列表。里面的成员也是列表,2层的。
主要就说下这两个参数吧。下面我们回到示例中来。我们看前面可以发现示例是一个orient为records的json字符串。
这样就好处理了。看代码:
# -*- coding: utf-8 -*-
"""
Created on Sun Aug 5 09:01:38 2018
@author: FanXiaoLei
"""
import pandas as pd
strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
df=pd.read_json(strtext,orient='records')
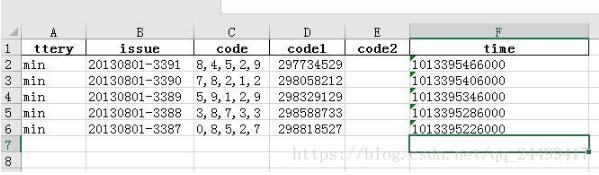
df.to_excel('pandas处理json.xlsx',index=False,columns=["ttery","issue","code","code1","code2","time"])
最终写入excel如下图:
以上这篇pandas处理json数据就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。