对python借助百度云API对评论进行观点抽取的方法详解
通过百度云API接口抽取得到产品评论的观点,也掠去了很多评论中无用的内容以及符号,为后续进行文本主题挖掘或者规则的提取提供基础。
工具
1、百度云账号,申请应用接口(自然语言处理)
2、python3.5
以下是百度接口提供的说明:
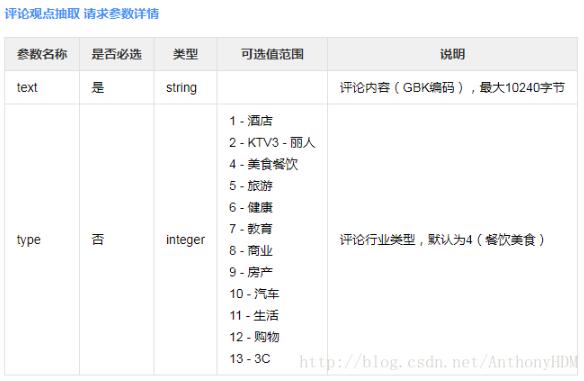
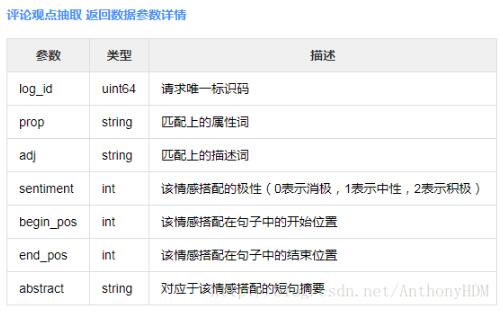
我们使用到的可选值是13,kindle属于3C产品。
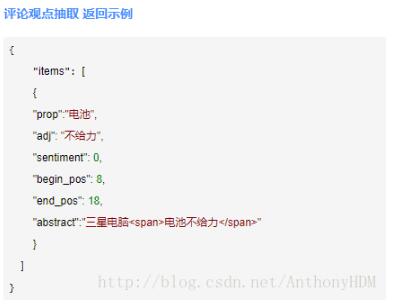
下面是代码示例:
from aip import AipNlp
import csv
import pandas as pd
from pandas.core.frame import DataFrame
""" 你的 APPID AK SK """
APP_ID = '********'
API_KEY = '********'
SECRET_KEY = '********'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# 导入评论数据文件,并找到第13列(12行)的评论内容提取出来
def output():
urls = []
with open('E:\\tb_iphone8.csv', "r") as f:
reader = csv.reader(f)
for row in reader:
urls.append(row[12])
return urls
# 通过百度云提供的API对评论观点进行提取
def commentTag():
x = output()
all={}
abst=''
for i in range(10560):
text=x[i]
""" 调用评论观点抽取 """
""" 如果有可选参数 """
# 可选参数为13表示利用了3C产品的语料库
options = {}
options["type"] = 13
""" 带参数调用评论观点抽取 """
result=client.commentTag(text, options)
print(result)
if "error_code" in result.keys():
abst+=''
all['abstract'] = abst
else:
data = result['items']
items = data[0]
abst += items['abstract']
all['abstract'] = abst
return abst
if __name__ == '__main__':
ALL=commentTag()
print(ALL)
得到的结果如下:

可以看到,现在抽取出来的评论部分内容都是具有一定观点倾向的,大部分没有什么含义的评论内容已经被除去,这对后面的分析有一定的帮助。
以上这篇对python借助百度云API对评论进行观点抽取的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。