pyhanlp安装介绍和简单应用
1. 前言
中文分词≠自然语言处理!
Hanlp
HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
功能:中文分词 词性标注 命名实体识别 依存句法分析 关键词提取新词发现 短语提取 自动摘要 文本分类 拼音简繁
中文分词只是第一步;HanLP从中文分词开始,覆盖词性标注、命名实体识别、句法分析、文本分类等常用任务,提供了丰富的API。
不同于一些简陋的分词类库,HanLP精心优化了内部数据结构和IO接口,做到了毫秒级的冷启动、千万字符每秒的处理速度,而内存最低仅需120MB。无论是移动设备还是大型集群,都能获得良好的体验。
不同于市面上的商业工具,HanLP提供训练模块,可以在用户的语料上训练模型并替换默认模型,以适应不同的领域。项目主页上提供了详细的文档,以及在一些开源语料上训练的模型。
HanLP希望兼顾学术界的精准与工业界的效率,在两者之间取一个平衡,真正将自然语言处理普及到生产环境中去。
我们使用的pyhanlp是用python包装了HanLp的java接口。
2. pyhanlp的安装和使用
2.1 python下安装pyhanlp
pip安装
sudo pip3 install pyhanlp
第一次import pyhanlp会下载一个比较大的数据集,需要耐心等待下,后面再import就不会有了。
from pyhanlp import *
详情请见pyhanlp官方文档
2.2 pyhanlp简单使用方法
分词使用
from pyhanlp import *
print(HanLP.segment("今天开心了吗?"))
>>> [今天/t, 开心/a, 了/ule, 吗/y, ?/w]
依存分析使用
from pyhanlp import *
print(HanLP.parseDependency("今天开心了吗?"))
>>> 1 今天 今天 nt t _ 2 状中结构 _ _
>>> 2 开心 开心 a a _ 0 核心关系 _ _
>>> 3 了 了 e y _ 2 右附加关系 _ _
>>> 4 吗 吗 e y _ 2 右附加关系 _ _
>>> 5 ? ? wp w _ 2 标点符号 _ _
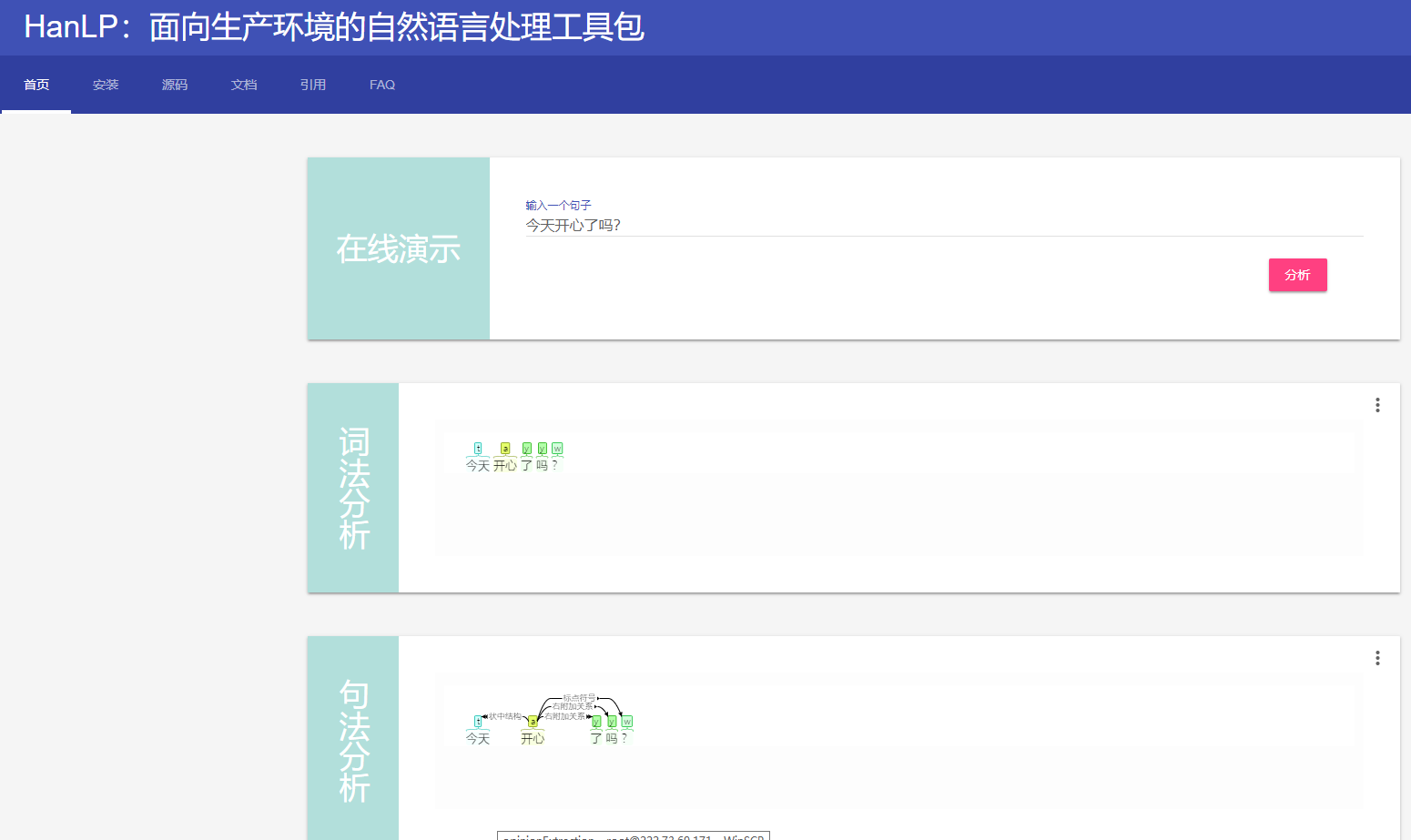
2.3 pyhanlp可视化
如果大家看不太清楚上面的输出,pyhanlp提供了一个很好的展示交付界面,只要一句命令就能启动一个web服务
hanlp serve
登录http://localhost:8765就能看下可视化界面,能看到分词结果和依存关系的结果,是不是很直观。这个网页上还有安装说明、源码链接、文档链接、常见的问题(FAQ)。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。