详解Python安装tesserocr遇到的各种问题及解决办法
Tesseract的安装及配置
在Python爬虫过程中,难免遇到各种各样的验证码问题,最简单的就是 这种验证码了,那么在遇到验证码的时候该怎么办呢?我们就需要OCR技术了,OCR-即Optical Character Recognition光学字符识别,是指通过扫描字符,然后将其形状翻译成电子文本的过程。而tesserocr是Python的一个OCR识别库,所以在安装tesserocr之前,我们需要安装tesseract这个东西
这种验证码了,那么在遇到验证码的时候该怎么办呢?我们就需要OCR技术了,OCR-即Optical Character Recognition光学字符识别,是指通过扫描字符,然后将其形状翻译成电子文本的过程。而tesserocr是Python的一个OCR识别库,所以在安装tesserocr之前,我们需要安装tesseract这个东西
下载地址:https://digi.bib.uni-mannheim.de/tesseract/可以选择下载不带dev的稳定版本,我下载的是3.05.01版本的,不过这个版本的可能比较早了,识别能力不是很厉害,读者可以选择下载最新版本的3.05.02,识别能力应该会好很多。
下载完就是一路双击,在最后的Additional Language data(download)选上这个选项,是OCR支持各种语言的包,然后继续安装,直到安装成功。
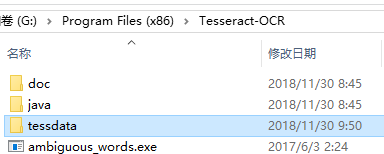
我的安装路径为:G:\Program Files (x86)\Tesseract-OCR
安装完成后就得需要配置环境变量,打开环境变量设置,在path中加入如下
 的设置,这样tesseract就安装成功并配置完成了、
的设置,这样tesseract就安装成功并配置完成了、
tesserocr库的安装
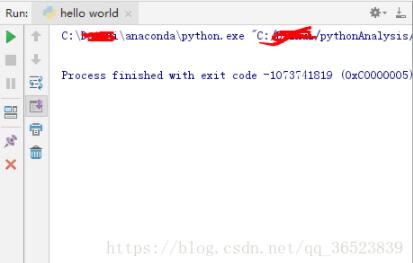
刚开始我直接在cmd下输入 pip install tesserocr 很不幸报错了,报错类似于如下。。。因为之前我的报错,没有截图。所以。。
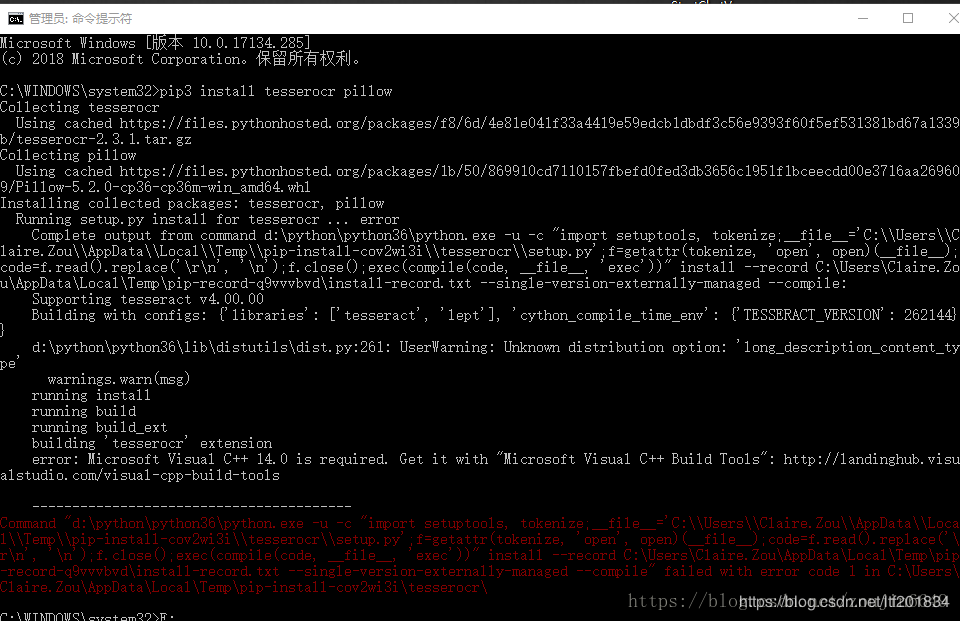
就是类似于这种的截图,这该怎么办,难道要去下载visual C++吗?我们有更好的解决方法,下载对应的.whl文件
下载地址:https://github.com/simonflueckiger/tesserocr-windows_build/releases一定要下载对应版本的
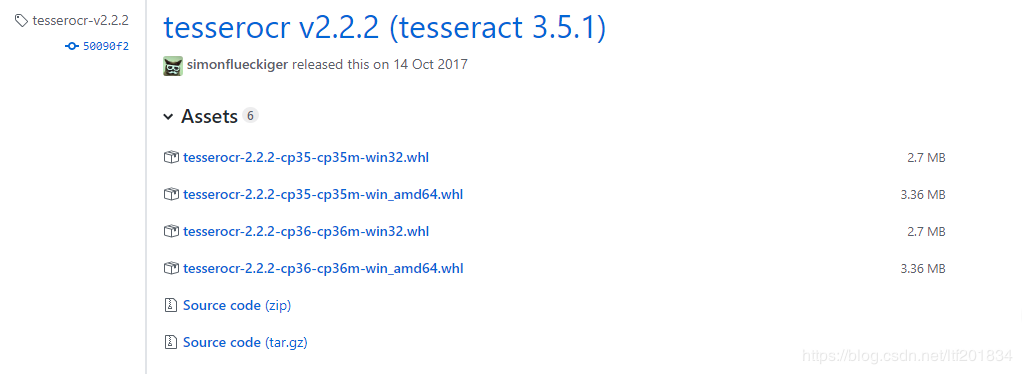
我的是3.5.1,所以我下载的是这个版本的。读者可以自行选择。
我的tesserocr-2.2.2-cp36-cp36m-win_amd64.whl文件下载在G盘根目录下,然后在cmd里输入 pip install G:\tesserocr-2.2.2-cp36-cp36m-win_amd64.whl 开始安装whl文件,发现报错了。提示不能安装whl文件。。原来是没有安装wheel。
然后我就去安装了wheel 直接 pip install wheel即可。
安装成功 在输入pip install G:\tesserocr-2.2.2-cp36-cp36m-win_amd64.whl 发现开始安装了。
哎心累啊,总算弄好了。但是,我在pycharm中调用tesserocr 这个库,他又提示报错了,这是为什么呢?百度了一下最终解决。
原来需要在pycharm下的terrminal下输入如下图:
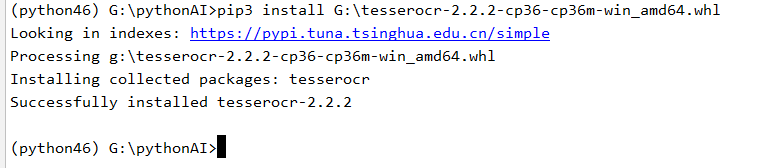
如果报错了还得有一步操作。
将Tesseract-OCR下的tessdata文件复制到你的Python安装路径的scripts下:
这样
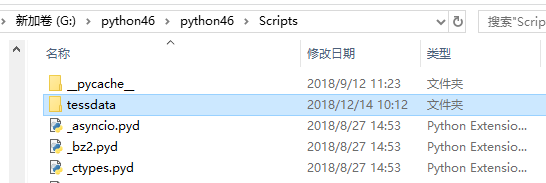
这下应该就彻底安装成功了。。
这下在pycharm里总算不会报错了,我们来试一下识别这两张图片的效果


代码:
from PIL import Image
import tesserocr
imag=Image.open('test.jpg')
print(tesserocr.image_to_text(imag))
imag1=Image.open('image.png')
print(tesserocr.image_to_text(imag1))
输出结果如下:

将762408识别成了162408 我也很无奈呀。。。可能是因为版本太菜了吧
以上就是我安装tesserocr遇到的问题及解决办法了。其实还可以装pytesseract这个库。
安装pytesseract库
安装这个pytesseract库可比tesserocr方便多了,根本不会报错,直接pip install pytesseract 完事。。pycharm直接搜索库

然后下载就完事,多省事。。。。
看一下识别效果,还是同样的两张图片。
代码:
import pytesseract
from PIL import Image
import tesserocr
im=Image.open('test.jpg')
print(pytesseract.image_to_string(im))
im1=Image.open('image.png')
print(pytesseract.image_to_string(im1))
运行结果:

运行结果一样的,所以我推荐大家使用pytesseract这个库。
验证码识别问题
我打开知乎登录界面,下载了一张验证码图片: 开始识别它。
开始识别它。
代码如下:
import pytesseract
from PIL import Image
import tesserocr
#简单验证 特别垃圾
image=Image.open('3.jpg')
result=tesserocr.image_to_text(image)
print(result)
#完全验证 也不咋地。。
image1=Image.open('3.jpg')
image1=image1.convert('L')
threshold=127
table=[]
for i in range(256):
if i <threshold:
table.append(0)
else:
table.append(1)
image2=image1.point(table,'1')
image2.show() #二值化灰度处理图片显示
result=pytesseract.image_to_string(image2)
print(result)
运行结果:
 都识别失败了,,,
都识别失败了,,,
贼无语,但是灰度化和二值化后的图片已经很清晰了。。
我都能看出来是H83G了,你识别个H535是个什么鬼。。综上,这个库吧,可能效果也不是那么好。先凑活用吧。。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。