详解小白之KMP算法及python实现
在看子串匹配问题的时候,书上的关于KMP的算法的介绍总是理解不了。看了一遍代码总是很快的忘掉,后来决定好好分解一下KMP算法,算是给自己加深印象。
在将KMP字串匹配问题的时候,我们先来回顾一下字串匹配的暴力解法:
假设字符串str为: "abcgbabcdh", 字串substr为: "abcd"
从第一个字符开始比较,显然两个字符串的第一个字符相等('a'=='a'),然后比较第二个字符也相等('b'=='b'),继续下去,我们发现第4个字符不相等了('g'!='d'),这时候我们让'g'和字串的开头'a'比较,若两者相同,则同时后移一位比较下一个字母,不同则将str中比较的字符后移一位,然后和字串中开始的'a'比较。以此类推....我们可以在str中找到substr字串,并返回字串的位置。
这种暴力搜索方法很显然时间复杂度是O(m*n) n,m分别表示str字符串和substr字串的长度。m*n的复杂度显然是比较大的,当m或者n很大的时候,时间开销会很大。KMP算法则可以将时间复杂度下降到O(m+n),和O(m*n)相比明显下降。
KMP算法和暴力搜索方法之间的差别在于KMP算法在出现字符串不相等的情况时,不需要返回到字串的开头重新比较。
如何保证字符串不相等的情况出现时,字串不从最开始开始比较呢,这时候临时数组就登场了。
书本上总是介绍说是,判断此时字串中是否有相同前缀和后缀,懵逼脸......
看完临时数组是如何构造的你应该差不多就知道前后缀问题了。
** 临时数组 ** : 我们假设子串为 'abcabg', 开始时j指向第一个字符,i指向第二个字符(j=0, i=1)。并且令pnext[0] = 0,如下图所示:
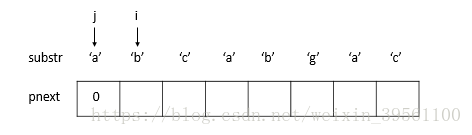
1) 由于substr[j] != substr[i] 并且j=0, 令pnext[i] = 0 , i往后移一位。(步骤1后,j=0, i=2)
2) 由于substr[j] != substr[i] 并且j=0, 令pnext[i] = 0 , i往后移一位。(步骤2后,j=0, i=3)
3) 此时substr[j] == substr[i], 令pnext[i] = j + 1, 并且 i , j 都后移一位。(步骤3后,j=1,i=4)
这时候我们来看一下临时数组的状态:
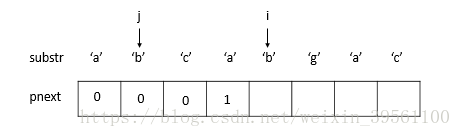
4) substr[j] == substr[i] 还是成立, 令pnext[i] = j+1, 并且i, j都后移一位。(j=2, i=5)
5) 此时 substr[j] != substr[i],由于j=2(不为0),令j = pnext[j-1] (由于pnext[j-1] = pnext[1] = 0 ==> j=0, 保持 i=5)
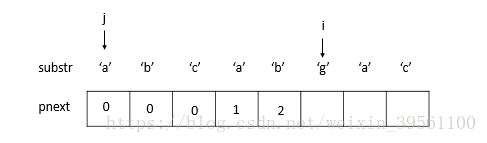
6) substr[j] != substr[i], 并且j=0, 令pnext[i] = 0, 并使i后移一位。(j=0, i=6)
7) substr[j] == substr[i], 同理pnext[i] = j+1 ,并且i, j都向后移动一位。(j=1, i=7)
8) substr[j] != substr[i], j != 0, j = pnext[j-1] = pnext[0] = 0。 (j=0, i=7)
9) substr[j] != substr[i], 且j=0, 令pnext[i] = 0。(此时i到达最后一个位置,并且pnext数组全部赋值完毕。pnext数组构造结束)
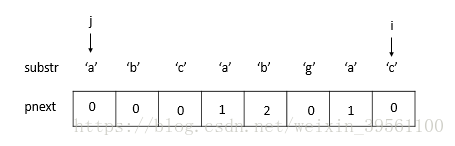
临时数组构造完毕之后,就可以使用 KMP算法 了。
还是假设 字符串str = 'abgabcabgacyf', 子串 substr = 'abcabgac'.
令i指向str的第一个字符,j指向substr第一个字符。KMP算法的详细运行步骤如下:
<1> str[i] == substr[j], i = i+1, j = j+1. (步骤1之后: i=1, j=1)
<2> str[i] == substr[j], i = i+1, j = j+1. (i=2, j=2)
<3> str[i] != substr[j], 此时j != 0, 所以临时数组pnext就派上用场了。令 j = pnext[j-1]. (i=2, j = pnext[2-1] = 0)
如果存在前后缀的话(即pnext[j-1]!=0),由于此步骤之前的substr与str相同(要不然 j 也不会往后移动了),这里举一个例子帮助理解:
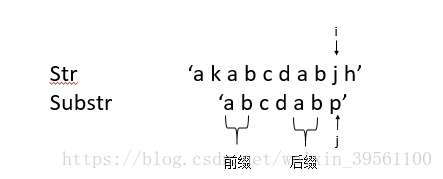
如图,当i和j位于图中时刻,字符j与p不相等。(p之前的abcdab肯定和上面相等,要不然j不会移动到字符p上),按照暴力搜索的方法是不是要让j和子串的第一个字符a比较呢。KMP算法就不需要,我们可以看到子串中p之前的字符存在最大相等前后缀为'ab', 那在下一次比较的时候‘ab'是不是就不用比较了呢。从而直接比较j和c呢??(如下图)这就是KMP算法的精髓所在。

<4> 这时候str[i] != substr[j], 但是和步骤<3>不一样的是,此时j=0(由于pnext[-1]不存在,j不能等于pnext[j-1]了)。所以子串开头只能和str中下一个字符比较,即i = i+1。(i=3, j=0)
<5> str[i] == substr[j] ==> i = i+1, j = j+1. (i=4, j=1)
<6> 以此类推。这一过程存在两种方法中止,即i或者j不能再加1(加1就会发生越界的时候)。假设str的长度为n,substr的长度为m。当j==m时,说明找到了子串,否则没有找到。
def KMP_algorithm(string, substring):
'''
KMP字符串匹配的主函数
若存在字串返回字串在字符串中开始的位置下标,或者返回-1
'''
pnext = gen_pnext(substring)
n = len(string)
m = len(substring)
i, j = 0, 0
while (i<n) and (j<m):
if (string[i]==substring[j]):
i += 1
j += 1
elif (j!=0):
j = pnext[j-1]
else:
i += 1
if (j == m):
return i-j
else:
return -1
def gen_pnext(substring):
"""
构造临时数组pnext
"""
index, m = 0, len(substring)
pnext = [0]*m
i = 1
while i < m:
if (substring[i] == substring[index]):
pnext[i] = index + 1
index += 1
i += 1
elif (index!=0):
index = pnext[index-1]
else:
pnext[i] = 0
i += 1
return pnext
if __name__ == "__main__":
string = 'abcxabcdabcdabcy'
substring = 'abcdabcy'
out = KMP_algorithm(string, substring)
print(out)
代码结果返回子串开始时的坐标位置。

看到这里如果还是没有懂得话,那就说明我表述的还不够好,推荐看看视频。
快速传送门:戳我
总结
以上所述是小编给大家介绍的详解小白之KMP算法及python实现,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
