Python使用pandas和xlsxwriter读写xlsx文件的方法示例
python使用pandas和xlsxwriter读写xlsx文件
已有xlsx文件如下:

1. 读取前n行所有数据
# coding: utf-8
import pandas as pd
# 1. 读取前n行所有数据
df = pd.read_excel('school.xlsx')#读取xlsx中第一个sheet
data1 = df.head(7) # 读取前7行的所有数据,dataFrame结构
data2 = df.values #list形式,读取表格所有数据
print("获取到所有的值:\n{0}".format(data1)) #格式化输出
print("获取到所有的值:\n{0}".format(data2)) #格式化输出
2. 读取特定行,特定列
# coding: utf-8
import pandas as pd
# 2. 读取特定行,特定列
df = pd.read_excel('school.xlsx') #读取xlsx中第一个sheet
data1 = df.ix[0].values #读取第一行所有数据,0表示第一行,不包含表头
data2 = df.ix[1,1] #读取指定行列位置数据
data3 = df.ix[[1,2]].values #读取指定多行
data4 = df.ix[:,[0]].values #读取指定列的所有行
#data4 = df[u'class'].values #同上
data5 = df.ix[:,[u'class',u'name']].values #读取指定键值列的所有行
print("数据:\n{0}".format(data1))
print("数据:\n{0}".format(data2))
print("数据:\n{0}".format(data3))
print("数据:\n{0}".format(data4))
print("数据:\n{0}".format(data5))
3. 获取xlsx文件行号,所有列名称
# coding: utf-8
import pandas as pd
# 3. 获取xlsx文件行号,所有列名称
df = pd.read_excel('school.xlsx') #读取xlsx中第一个sheet
print("输出行号列表{}".format(df.index.values)) # 获取xlsx文件的所有行号
print("输出列标题{}".format(df.columns.values)) #所有列名称
4. 读取xlsx数据转换为字典
# coding: utf-8
import pandas as pd
# 4. 读取xlsx数据转换为字典
df = pd.read_excel('school.xlsx') #读取xlsx中第一个sheet
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['id','name','class','data','stature']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
5. 写xlsx文件
#coding: utf-8
import xlsxwriter
# 创建工作簿
file_name = "first_book.xlsx"
workbook = xlsxwriter.Workbook(file_name)
# 创建工作表
worksheet = workbook.add_worksheet('sheet1')
# 写单元格
worksheet.write(0, 0, 'id')
worksheet.write(0,1, 'name')
worksheet.write(0,2, 'class')
worksheet.write(0,3, 'data')
# 写行
worksheet.write_row(1, 0, [1, 2, 3])
# 写列,其中列D需要大写
worksheet.write_column('D2', ['a', 'b', 'c'])
# 关闭工作簿
workbook.close()
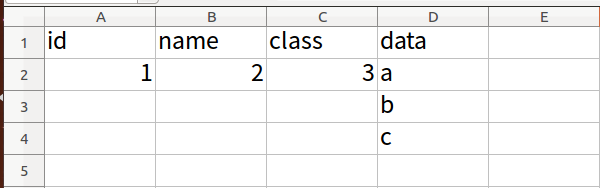
写入的xlsx文件如下:
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接