Django之无名分组和有名分组的实现
在Django 2.0版本之前,在urls,py文件中,用url设定视图函数
urlpatterns = [ url(r'login/',views.login), ]
其中第一个参数是正则匹配,如下代码,输入http://127.0.0.1:8000/login,出现的是login页面,但是输入login2,出现的还是login页面,这是因为Django会将匹配成功的返回,不会继续往下匹配
urlpatterns = [ url(r'login',views.login), url(r'login2',views.login2), ]
所以为了避免上面这种情况,可以在第一个参数加上正则表达式
urlpatterns = [ url(r'^login/$',views.login), url(r'^login2/$',views.login2), ]
^ 号限定开头,$限定结尾,' / '为匹配机制,比如第一次输入:http://127.0.0.1:8000/login,没有匹配成功,系统会自动加上‘/‘再进行一次匹配
这样就可以写出首页和尾页(尾页是指找不到对应页面时打开的页面,俗称404)
urlpatterns = [ url(r'^$',views.home), #这是首页 url(r'',views.error) #这是尾页 ]
同样的既然可以进行正则匹配,那么就可以写更多的正则语法:
urlpatterns = [
url(r'^login/[0-9]{4}$',views.login),
]
类似上面写出的正则,就是login/ 后面随意加上4位数字都可以访问login页面
同样的正则还有分组的概念,但是在Django中把分组分为两种:无名分组和有名分组
无名分组:
urlpatterns = [
url(r'^login/([0-9]{4})$',views.login),
]
在普通的正则匹配中加上()就是无名分组,那么这样有什么意义呢?
首先在后端的views上,会得到一个分组的参数,以上面代码为例,那么views.login函数的参数除了request,还需要添加一个参数(名字随意),进行几次分组那么就需要多添加几次参数
进入view页面,其中xxx的名字是随意的,传进来的分组的数据例如我输入的网址是:login/222,那么xxx的值为222
def login(request,xxx): print(xxx)
有名分组:
有名分组其实就是在无名的分组的基础上加上了名字
urlpatterns = [
url(r'^login/(?P<year>[0-9]{4})$',views.login),
]
语法为:(?P<名字> 正则表达式),就是在无名分组的括号里面加上了?P<名字>,注意其中P为大写
既然有了名字,那么在views页面就不能给函数传递随意的参数了:
def login(request,year): print(year)
第二个参数year是urls页面命名的名字:
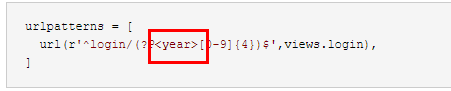
如果名字不一样则会报错
这里有一个坑,既然分组有有名分组和无名分组,那么能不能一起使用?
答:不行,别问,问就是不行
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。