python lxml中etree的简单应用
我一般都是通过xpath解析DOM树的时候会使用lxml的etree,可以很方便的从html源码中得到自己想要的内容。
这里主要介绍一下我常用到的两个方法,分别是etree.HTML()和etree.tostrint()。
1.etree.HTML()
etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
如果想通过xpath获取html源码中的内容,就要先将html源码转换成_Element对象,然后再使用xpath()方法进行解析。例如,这里有一段最简单的html源码:"<html><body><h1>This is a test</h1></body></html>",现在想要得到h1标签中的文本,可以这样实现:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This is a test</h1></body></html>'
# 将html转换成_Element对象
_element = etree.HTML(html)
# 通过xpath表达式获取h1标签中的文本
text = _element.xpath('//h1/text()')
print 'result is: ', text
结果:
result is: ['This is a test']
通过结果可以知道,xpath()方法放回的结果是一个列表,所以通常在取xpath()方法结果的时候,只取列表中的第一个元素。
2.etree.tostring()
etree.tostring()方法用来将_Element对象转换成字符串。一般通过简单的xpath表达式无法得到想要的内容的时候我就会用该方法。例如,将上面的html小改动一下:"<html><body><h1>This <a>is a </a>test</h1></body></html>",这时候如果想要得到h1中的文本该怎么办呢?使用“//h1/text()”试试(将上面的html保存并用火狐浏览器打开,然后在FirePath中输入该xpath表达式):
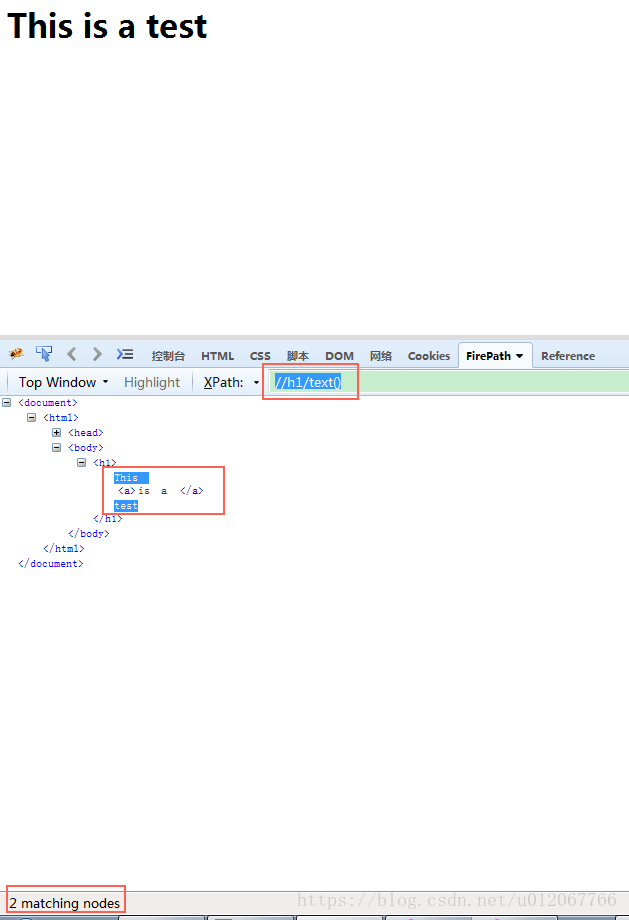
通过截图左下角的提示可以知道,使用xpath表达式“//h1/text()”只能得到h1标签中文本的“This”和“test”,用代码实现看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1/text()')
print 'result is: ', text
运行结果:
result is: ['This ', 'test']
确实,使用xpath()方法,只能得到h1中部分文本内容,我们再试试使用“//h1//text()”看看:
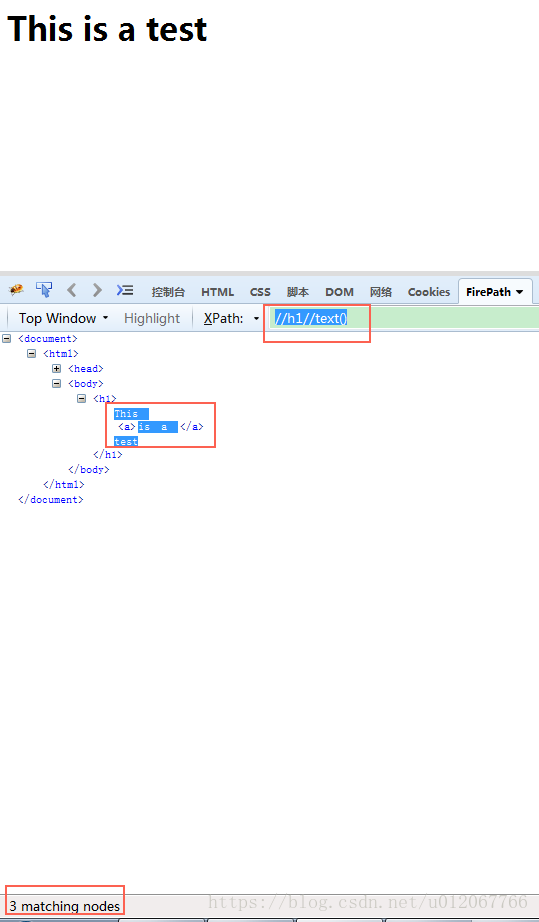
然后通过代码实现看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1//text()')
print 'result is: ', text
运行结果:
result is: ['This ', 'is a ', 'test']
通过“//h1//text()”表达式确实可以得到想要的内容,但是得到的是一个列表,还需要将列表中的所有元素“拼”起来才行,是不是有点麻烦。这时候,就可以考虑使用etree.tostring()方法了,etree.tostring()方法可以传递多个参数,包括element_or_tree、encoding、method等,其中method参数为text的时候,表示返回_Element对象中的所有文本,所以可以这样:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
# 先找到h1对象,然后通过etree.tostring方法找到h1对象中的所有文本
_h = _element.xpath('//h1')
# 注意,xpath方法返回的是一个列表,我们需要的是列表中的第一个元素:代表h1标签的_Element对象
result = etree.tostring(_h[0], method='text')
print 'result is: ', result
运行结果:
result is: This is a test
这时候使用etree.tostring()方法是不是很容易的就解决问题了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。